skiplist简介
skip List是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)(大多数情况下),因为其性能匹敌红黑树且实现较为简单,因此在很多著名项目都用跳表来代替红黑树,例如LevelDB、Redis的底层存储结构就是用的SkipList。
目前常用的key-value数据结构有三种:Hash表、红黑树、SkipList,它们各自有着不同的优缺点:
Hash表:插入、查找最快,为O(1);如使用链表实现则可实现无锁;数据有序化需要显式的排序操作。
红黑树:插入、查找为O(logn),但常数项较小;无锁实现的复杂性很高,一般需要加锁;数据天然有序。
SkipList:插入、查找为O(logn),但常数项比红黑树要大;底层结构为链表,可无锁实现;数据天然有序。
SkipList基本数据结构及其实现
一个跳表,应该具有以下特征:
1、一个跳表应该有几个层(level)组成;
通常是10-20层,leveldb中默认为12层。
2、跳表的第0层包含所有的元素;
且节点值是有序的。
3、每一层都是一个有序的链表;
层数越高应越稀疏,这样在高层次中能’跳过’许多的不符合条件的数据。
4、如果元素x出现在第i层,则所有比i小的层都包含x;
5、每个节点包含key及其对应的value和一个指向该节点第n层的下个节点的指针数组
x->next[level]表示第level层的x的下一个节点
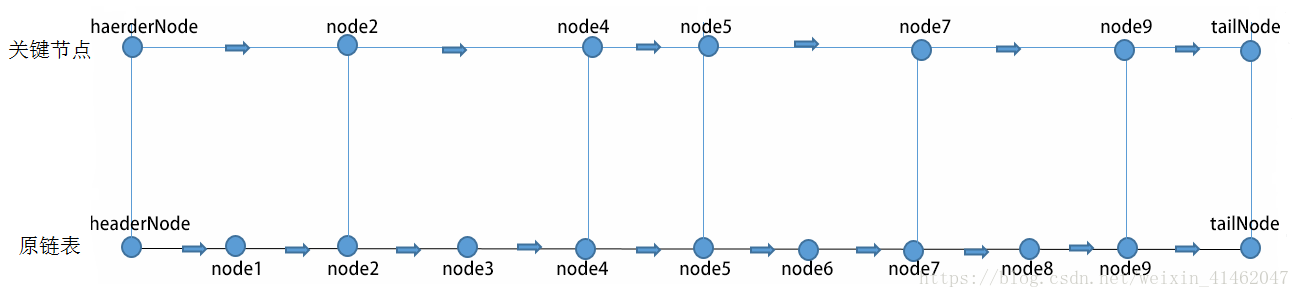
一个有序的链表,我们选取它的一半的节点用来建索引,这样如果插入一个节点,我们比较的次数就减少了一半。这种做法,虽然增加了50%的空间,但是性能提高了一倍。如上图。既然,我们已经提取了一层节点索引,那么,可以在第一层索引上再提取索引。如下图。
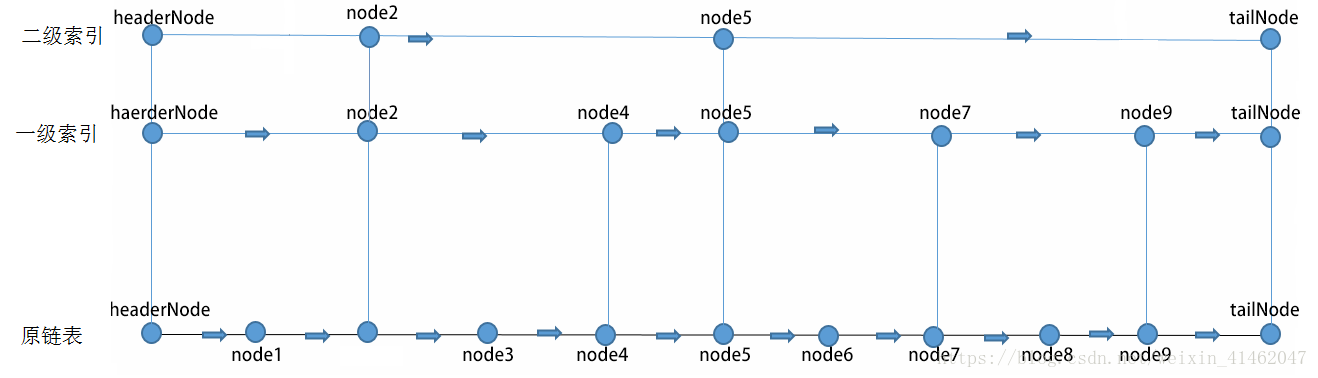
对于node5来说,它的next:1
2
3node5->next[2] = tailNode;
node5->next[1] = node7;
node5->next[0] = node6;
对于node7来说,它的next:1
2node7->next[1] = node9;
node7->next[0] = node8;
对于node3来说,它的next:1
node3->next[0] = node4;
skiplist查找
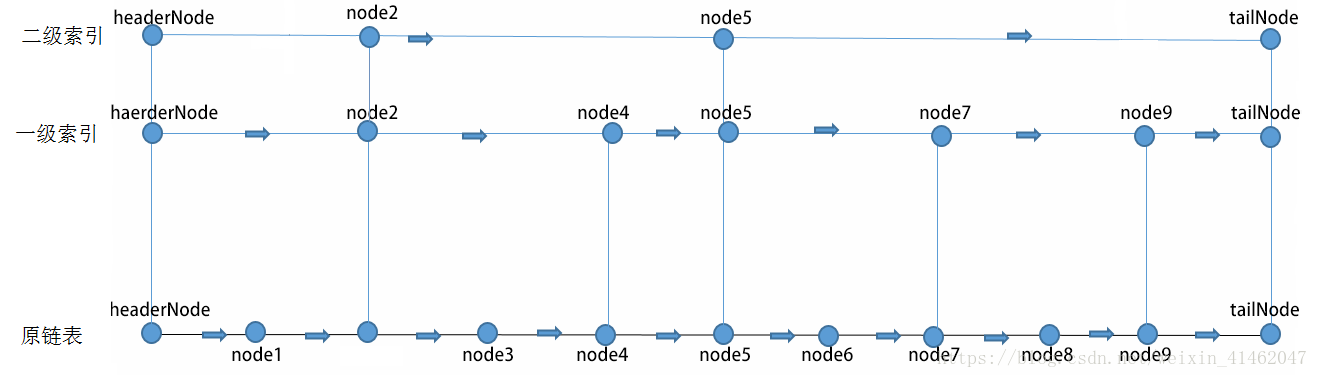
综上:
当targetNode->next[i]的值 < 待查找的值时,令targetNode = targetNode->next[i],targetNode移到第i级的下一个结点;
当targetNode->next[i]的值 > 待查找的值时,向下降级,i- - ,不改变targetNode;
当targetNode->next[i]的值 = 待查找的值时,向下降级,i- - ,不改变targetNode。
最后,再次比较targetNode->next[0]和theElement,判断是否找到。
所以整个运算下来,targetNode是要查找的节点前面那个节点。1
2
3
4
5
6
7
8
9
10
11
12/* 如果存在 x, 返回 x 所在的节点,
* 否则返回 x 的后继节点 */
find(x)
{
p = top;
while (1) {
while (p->next->key < x)
p = p->next;
if (p->down == NULL)
return p->next;
p = p->down;
}
skiplist插入
插入的步骤:
新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
把索引插入到原链表。O(1)
利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
总体上,跳表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
skiplist删除
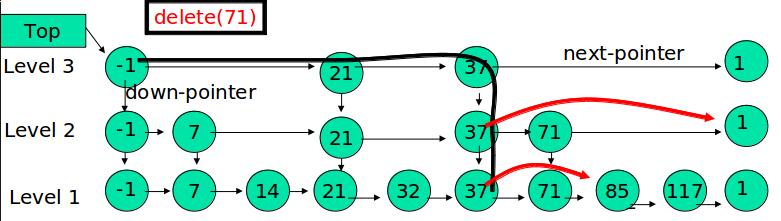
自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳表删除操作的时间复杂度是O(N)
skiplist实现
1 | package com.hqq.list; |
1 | package com.hqq.list; |