分类
数字、字符串、列表、元组、字典、集合
数字
- python整数不分类型,或者说它只有一种类型的整数。Python 整数的取值范围是无限的,不管多大或者多小的数字,Python 都能轻松处理。
当所用数值超过计算机自身的计算能力时,Python 会自动转用高精度计算(大数计算)。 - python 只有一种小数类型,就是 float。
- 复数(Complex)是python的内置类型,直接书写即可。换句话说,Python 语言本身就支持复数,而不依赖于标准库或者第三方库。复数由实部(real)和虚部(imag)构成,在Python中,复数的虚部以j或者j作为后缀。
- 布尔值型bool 真 1 True,假 0 False
字符串
字符串是由独立字符组成的一个序列,通常包含在单引号(’’)双引号(””)或者三引号之中(’’’ ‘’’或””” “””,两者一样)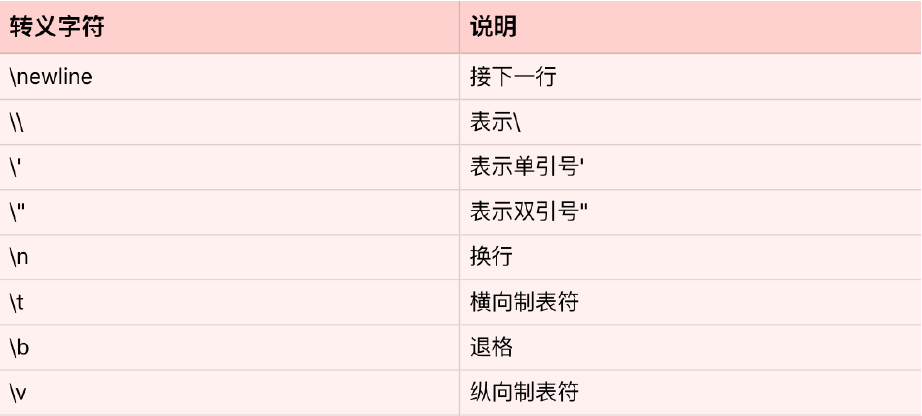
- 常用操作
1 | # capitalize / swapcase / title |
1 | # string.capitalize() #把字符串的第一个字符大写 |
元组 & 列表
- 元组也称为只读列表,数据只可以被查询,不能被修改。字符串的切片操作同样适用于列表。列表用()标示,黎明的元素用逗号隔开。如(1,2,3)
- 列表是python的基础数据类型之一,是用[]括起来,每个元素以逗号隔开,里面可以存放各种数据类型。如:li = [‘sunshine’,18,{‘hobby’:’eat’},[1,2,3]]。列表还可以储存大量数据,32位python的限制是536870912个元素,64位python的限制是1152921504606846975 个元素。列表是有序的,有索引值,可以切片,方便取值。
- 列表和元组的存储方式的差异
1 由于列表是动态的,所以它需要存储指针,来指向对应的元素(上述例子中,对于int 型,8 字节)。另外,由于列表可变,所以需要额外存储已经分配的长度大小(8 字节),这样才可以实时追踪列表空间的使用情况,当空间不足时,及时分配额外空间。,Python 每次分配空间时都会额外多分配一些,这样的机制(over-allocating)保证了其操作的高效性:增加 / 删除的时间复杂度均为 O(1)。
2 元组长度大小固定,元素不可变,所以存储空间固定。 - 列表和元组的区别
1 列表是动态的,长度可变,可以随意的增加、删减或改变元素。列表的存储空间略大于元组,性能略逊于元组。
2 元组是静态的,长度大小固定,不可以对元素进行增加、删减或者改变操作。元组相对于列表更加轻量级,性能稍优。 - 列表和元组的使用场景
1 如果存储的数据和数量不变,比如你有一个函数,需要返回的是一个地点的经纬度,然后直接传给前端渲染,那么肯定选用元组更合适。
2 如果存储的数据或数量是可变的,比如社交平台上的一个日志功能,是统计一个用户在一周之内看了哪些用户的帖子,那么则用列表更合适。
1 | # insert / append / extend |
字典
字典是Python中唯一的映射类型,采用键值对(key–>value)的形式存储数据。Python对key进行哈希函数运算,根据运算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示kye必须是不可变类型,如:数组、字符串、元组。字典是除列表之外最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象结合。两者的区别在于:字典是通过key来取值的,而不是通过偏移存取。1
2
3
4
5
6
7
8
9
10dic = {'name':'sunshine','age':28,'sex':'male'}
dic['li'] = ['a','b']
print(dic) # {'name': 'sunshine', 'age': 28, 'sex': 'male', 'li': ['a', 'b']}
# setdefault在字典中增加键值对,如果只有键那对应的值就是none,但是如果原字典中存在设置的键值对,则不会发生变更
#{'name': 'sunshine', 'age': 28, 'sex': 'male', 'li': ['a', 'b'], 'hobby': ['study', 'listen', 'eat']}
dic.setdefault('hobby',['study','sleep','eat']) # 未发生变化
#{'name': 'sunshine', 'age': 28, 'sex': 'male', 'li': ['a', 'b'], 'hobby': ['study', 'listen', 'eat']}
print(dic)
setdefaut