基本概念
- 文档
- Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
- 文档会被序列化为JSON格式,保存在Elasticsearch中,JSON对象由字段组成,每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
- 每个文档都有一个Unique ID,可以自己指定ID,或者通过Elasticsearch生成
- JSON文档
- 一篇文档包含了一系列的字段。类似数据库表中一条记录
- JSON文档,格式灵活,不需要预先定义格式;字段的类型可以指定或者通过Elasticsearch自动推算,支持数组/支持嵌套
- 文档的元数据
元数据,用于标注文档的相关信息
_index:文档所属的索引名
_type:文档所属的类型名
_id:文档唯一Id
_source:文档的原始Json数据
_all:整合所有字段内容到该字段,已被废除
_version:文档的版本信息
_score:相关性打分 - 索引
- 索引是文档的容器,是一类文档的结合;Index体现了逻辑空间的概念,每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型;Shard体现了物理空间的概念,索引中的数据分散在Shard上。
- 索引的Mapping与Settings:Mapping定义文档字段的类型,Setting定义不同的数据分布
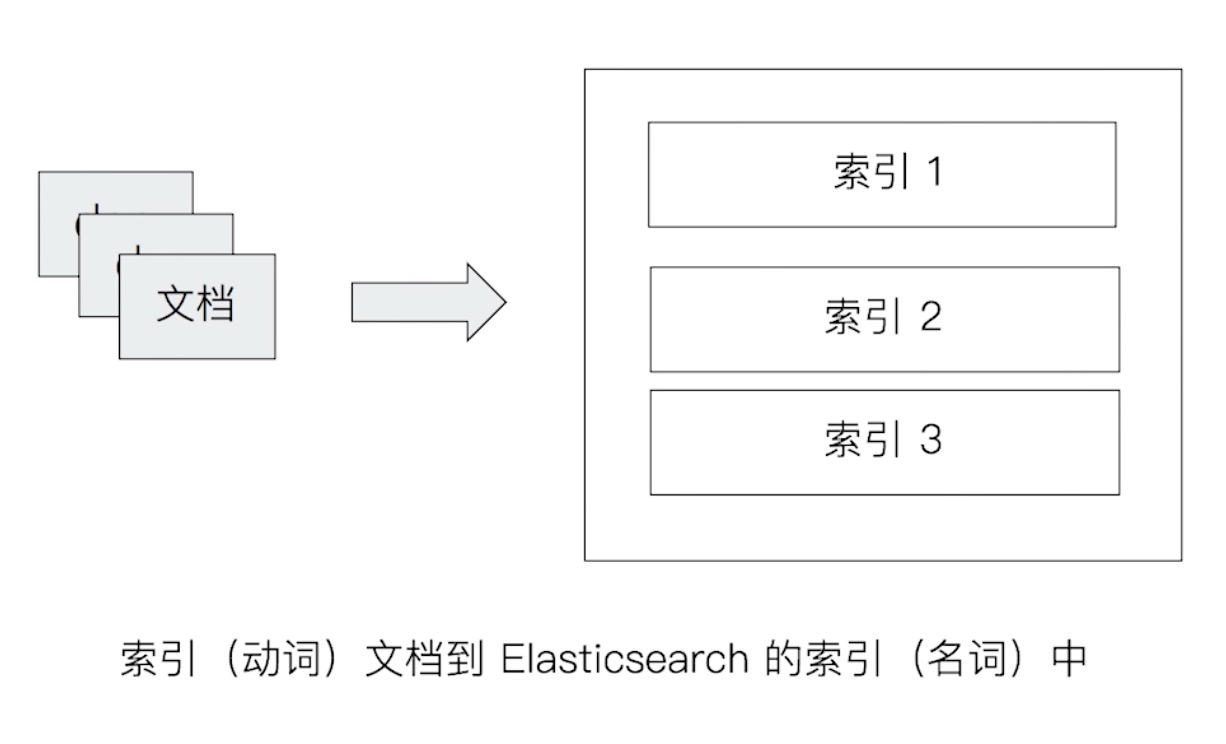
- 与关系型数据库对比
节点、集群
- 分布式系统的可用性与扩展性
- 高可用性:服务可用性,允许有节点停止服务;数据可用性,部分节点丢失,不会丢失数据;
- 可扩展性:请求量提升/数据的不断增长(将数据分布到所有节点上)
- Elasticsearch的分布式架构好处:存储的水平扩容,提高系统的可用性;部分节点停止服务,整个集群的服务不受影响;
- Elasticsearch的分布式架构:不同的集群通过不同的名字来区分,默认名字“elasticsearch”;通过配置文件修改,或者命令行中”-E cluster.name=geektime”进行设定;一个集群可以有一个或多个节点;
- 节点
- 节点是一个Elasticsearch的实例,本质上就是一个JAVA进程,一台机器上可以运行多个Elasticsearch进程,但生产环境一般只建议一台机器上只运行一个Elasticsearch实例。
- 每一个节点都有名字,通过配置文件配置或启动时候“-E node.name=node1”指定;
- 每一个节点在启动之后,会分配一个UID,保存在data目录下。
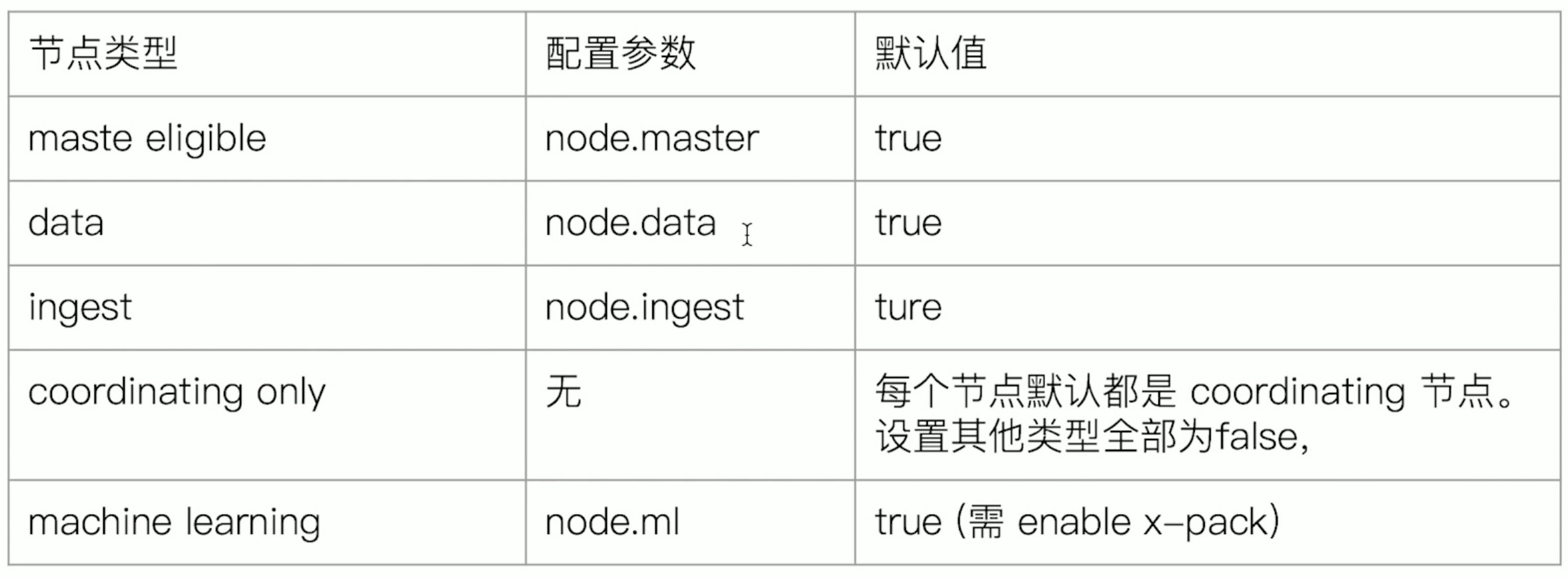
- Master-eligible nodes 和Master Node
- 每个节点启动后,默认就是一个Master eligible节点,可以设置node.master:false禁止;
- Master-eilgible节点可以参加选主流程,成为Master节点;当第一个节点启动时候,它会将自己选举成Master节点;
- 每个节点上都保存了集群的状态,只有Master节点才能修改集群的状态信息;集群状态(cluster State),维护了一个集群中必要的信息,包括所有的节点信息,所有的索引和其相关的Mapping与Setting信息;分片的路由信息;任意节点都能修改信息会导致数据的不一致性;
- Date Node & Coordinating Node
- Data Node:可以保存数据的节点,叫做Data Node。负责保存分片数据,在数据扩展上起到了至关重要的作用。
- Coordinating Node: 负责接受client的请求,将请求分发到合适的节点,最终把结果汇集到一起;每个节点默认都起到了Coordinating Node的职责。
- 其他节点
- Hot & Warm节点:不同硬件配置的Data Node,用来实现Hot&Warm架构,降低集群部署的成本
- Machine Learning Node:负责跑机器学习的Job,用来做异常检测;
- 主分片:用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上。一个分片是一个运行的Lucene的实例,主分片数在索引创建时指定,后续不允许修改,除非Reindex。
- 副本:用以解决数据高可用的问题,分片是主分片的拷贝。副本分片数可以动态调整;增加副本数还可以在一定程度上提高服务的可用性。
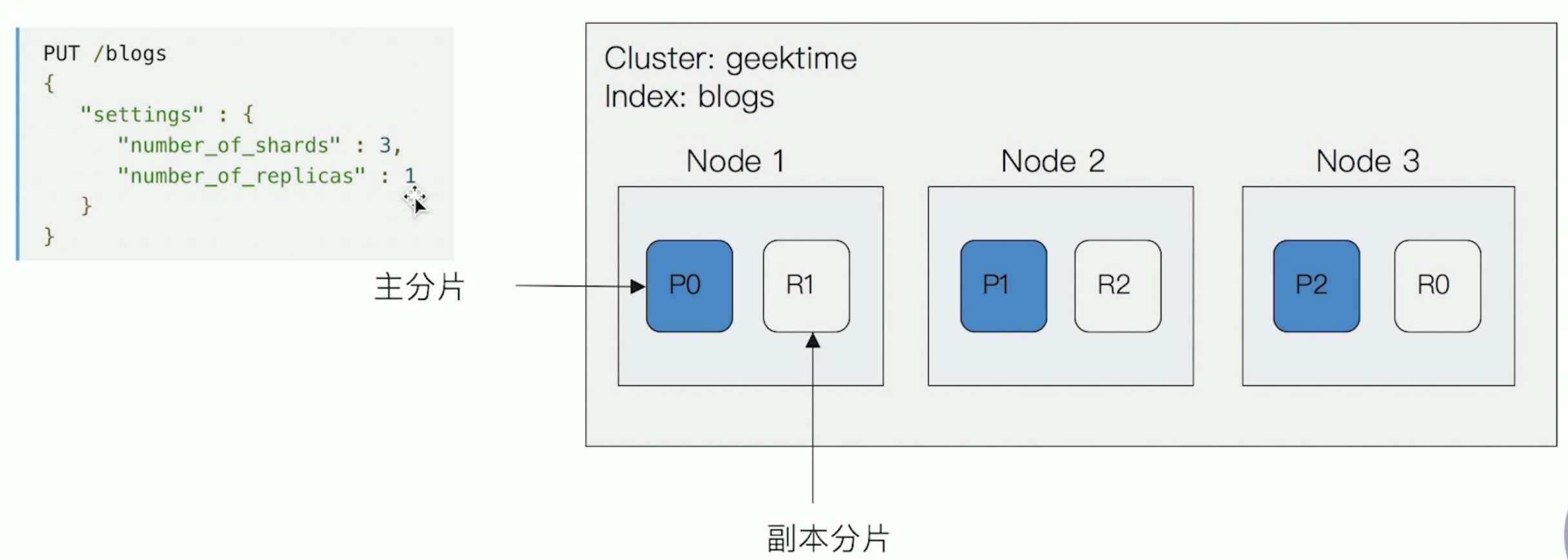
- 分片的设定
- 对于生产环境中分片的设定,需要提前做好容量规划。
- 分片数设置过小,导致后续无法增加节点实现水平扩展;单个分片的数据量太大,导致数据重新分配耗时。
- 分片数设置过大,7.0开始,默认主分片设置成1,解决了over-sharding的问题;影响搜索结果的相关性打分,影响统计结果的准确性;单个节点上过多的分片,会导致资源浪费,同时也会影响性能。

基本CRUD操作

- Type名: 约定都用_doc
- Create: 如果ID已经存在,会失败;
- Index: 如果ID不存在,创建现有的文档。否则,先删除现有的文档,在创建新的文档,版本会增加;
- Update: 文档必须已经存在,更新只会对相应字段做增量修改;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
941. Create 一个文档
PUT users/_create/2
{
"firstName":"Jack",
"lastName":"Johnson",
"tags":["guitar","skateboard"]
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
支持自动生成文档Id和指定文档Id两种方式
通过调用“post /users/_doc”,系统会自动生成document Id
使用HTTP PUT user/_create/1创建时,URI中显示指定_create,此时如果该id文档已经存在,操作失败。
2. GET 一个文档
GET users/_doc/1
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"firstName" : "Jack",
"lastName" : "Johnson",
"tags" : [
"guitar",
"skateboard"
]
}
}
找到文档,返回HTTP 200;
文档元信息,_index/_type/
版本信息,同一个Id的文档,即使被删除,Version号也会不断增加;
_source中默认包含了文档的所有原始信息
- 找不到文档,返回HTTP 404
3. Index 文档
PUT users/_doc/1
{
"tags":["guitar","skateboard","reading"]
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
Index和Create不一样的地方:如果文档不存在,就索引新的文档。
否则现有文档会被删除,新的文档被索引。版本信息+1
POST users/_update/1
{
"doc":{
"albums":["album1","album2"]
}
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "noop",
"_shards" : {
"total" : 0,
"successful" : 0,
"failed" : 0
}
}
update方法不会删除原来的文档,而是实现真正的数据更新
post方法/payload需要包含在doc中
Bulk API
- 支持在一次API调用中,对不同的索引进行操作
- 支持四种类型操作Index/Create/Update/Delete
- 可以再URI中指定Index,也可以在请求的Payload中进行
- 操作中单条记录失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156POST _bulk
{ "index" : {"_index": "test","_id":"1"}}
{ "field1": "value1"}
{ "delete": {"_index": "test","_id":"2"}}
{ "create": {"_index": "test2","_id":"3"}}
{ "field1": "value3"}
{ "update": {"_index": "test","_id":"1"}}
{"doc":{"field2":"value2"}}
{
"took" : 717,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"delete" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 404
}
},
{
"create" : {
"_index" : "test2",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 200
}
}
]
}
批量读取-mget,批量操作可以减少网络连接所产生的开销,提高性能
GET _mget
{
"docs":[
{
"_index":"user",
"_id":1
},
{
"_index":"comment",
"_id":1
}
]
}
{
"docs" : [
{
"_index" : "user",
"_type" : null,
"_id" : "1",
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [user]",
"resource.type" : "index_expression",
"resource.id" : "user",
"index_uuid" : "_na_",
"index" : "user"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [user]",
"resource.type" : "index_expression",
"resource.id" : "user",
"index_uuid" : "_na_",
"index" : "user"
}
},
{
"_index" : "comment",
"_type" : null,
"_id" : "1",
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [comment]",
"resource.type" : "index_expression",
"resource.id" : "comment",
"index_uuid" : "_na_",
"index" : "comment"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [comment]",
"resource.type" : "index_expression",
"resource.id" : "comment",
"index_uuid" : "_na_",
"index" : "comment"
}
}
]
}
其他:msearch批量查询
错误返回:
无法连接:网络故障或集群挂了
连接无法关闭:网络故障或节点错误
429:集群过于繁忙
4xx:请求体格式有错
500:集群内部错误