基本概念
- 概念
- 正排索引-文档Id到文档内容和单词的关联;
- 倒排索引- 单词到文档Id的关系;
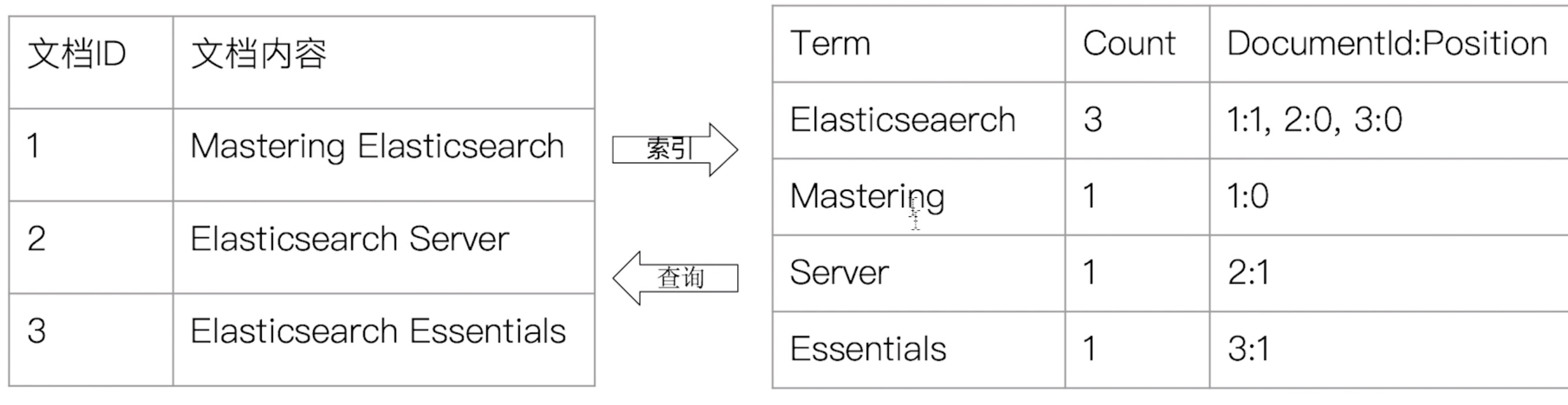
- 核心组成
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词倒排列表的关联关系;单词词典一般比较大,可以通过B+树或哈希拉链法实现,以满足性能的插入与查询;
- 倒排列表(Posting List),记录了单词对应的文档结合,由倒排索引项组成;倒排索引项(Posting)由文档ID、词频TF(该单词在文档中出现的次数,用于相关性评分)、位置(Postion)(单词在文档中的位置,用于语句搜索phrase query)、偏移(offset)(记录单词的开始结束位置,实现高亮显示)
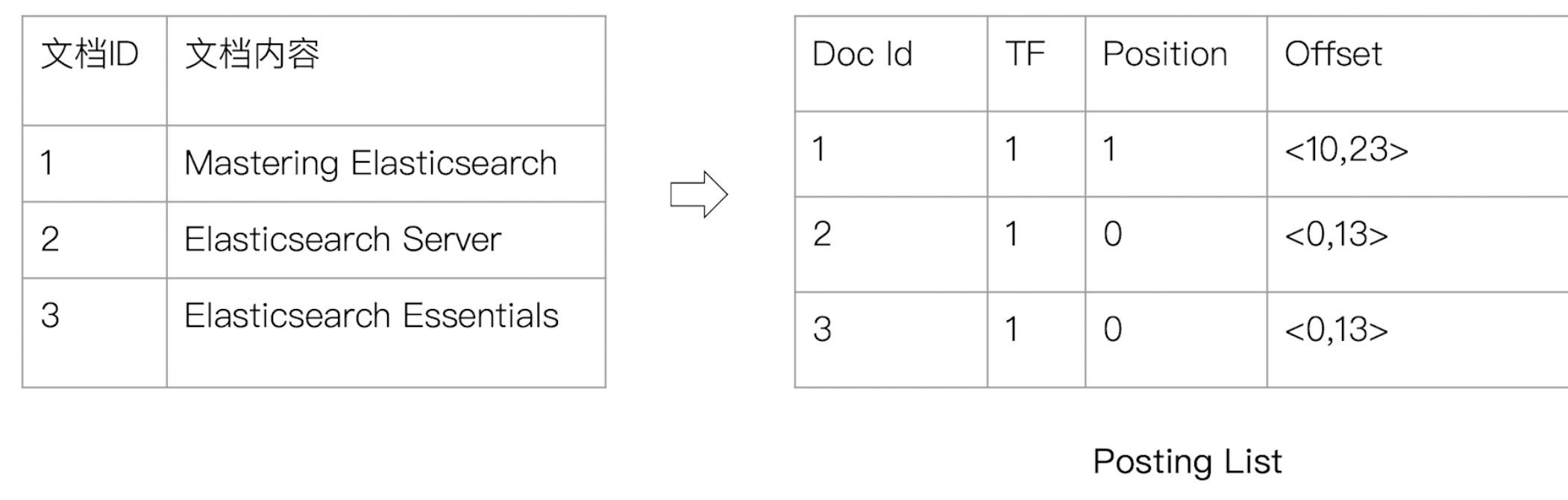
- Elasticsearch的倒排索引
- Elasticsearch的JSON文档中的每个字段,都有自己的倒排索引
- 可以指定对某些字段不做索引,优点是节省存储空间,缺点是字段无法被搜索
Analysis与Analyzer
- Analysis
- Analysis:文本分析是把全文本转换一系列单词(term/token)的过程,也叫分词;
- Analysis是通过Analyzer来实现的,可使用Elasticsearch内置的分析器/或者按需定制化分析器
- 除了在数据写入时转换词条,匹配query语句时侯也需要相同的分析器对查询语句进行分析
- Analyzer
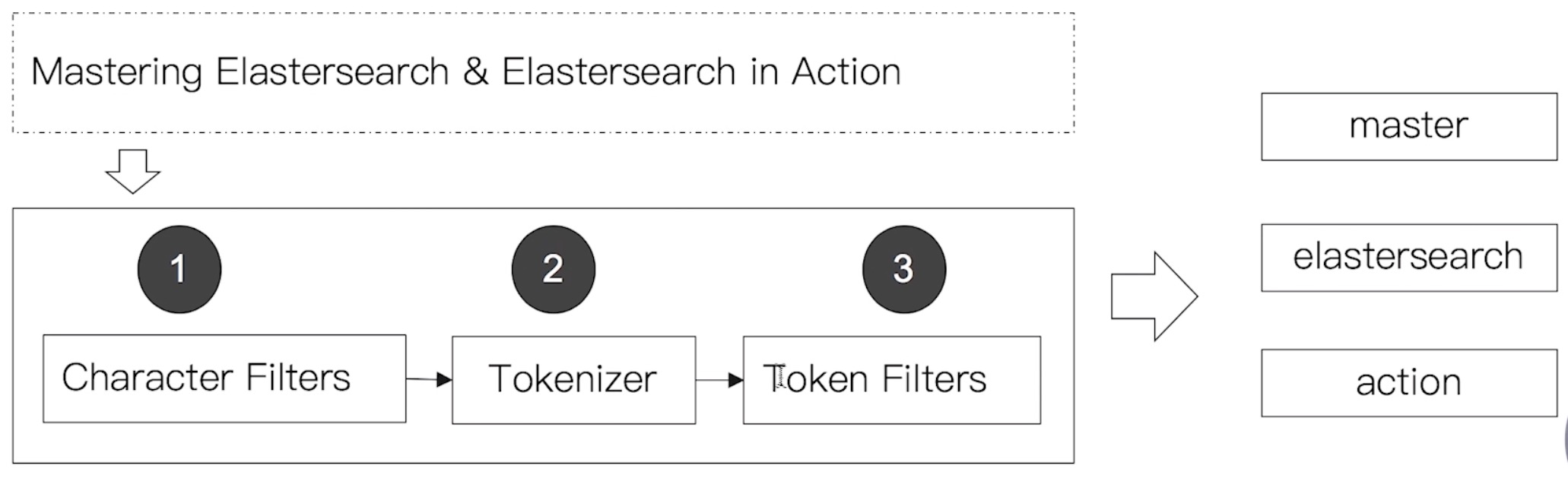
分词器是专门处理分词的组件,Analyzer由三部分组成
- Character Filters:针对原始文本处理,例如去除html
- Tokenizer:按照规则切分为单词
- Token Filter:将切分的单词进行加工,小写,删除stopwords,增加同义词;
- Elasticsearch的内置分词器
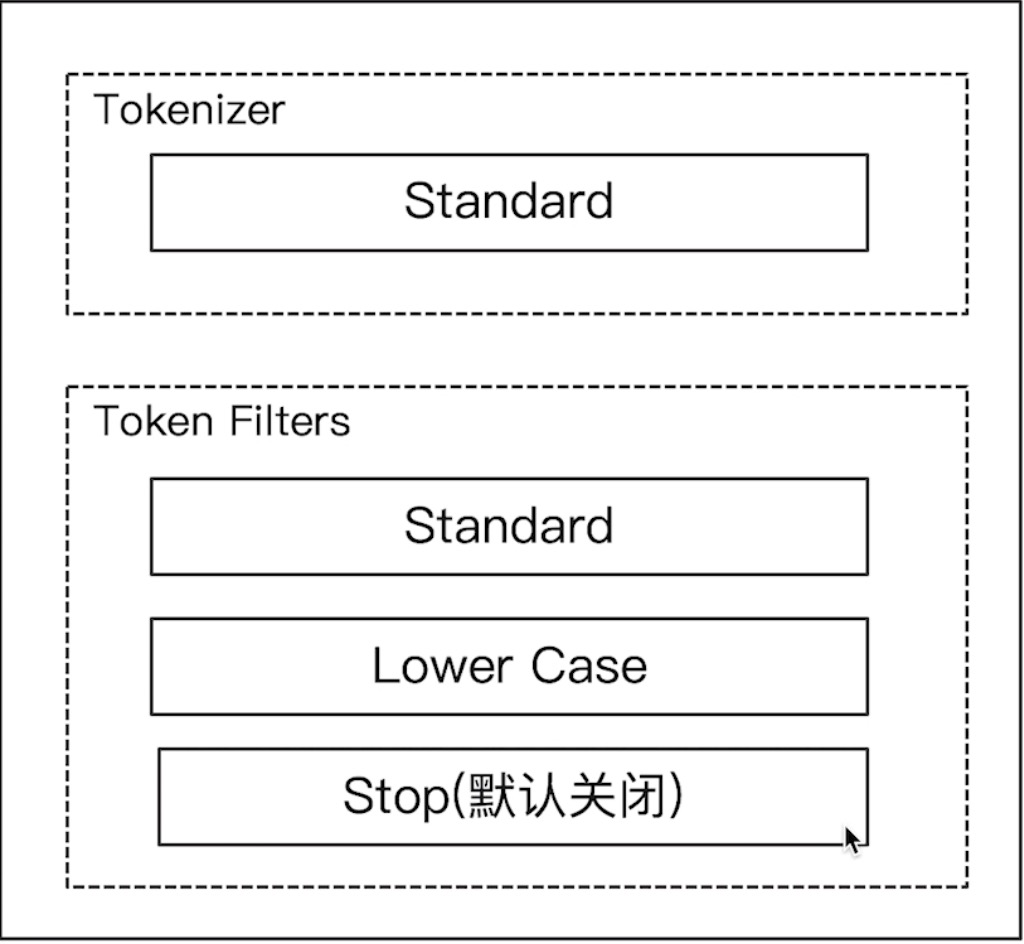
- Standard Analyzer:默认分词器,按词切分,小写处理
- Simple Analyzer:按照非字母切分(符号被过滤),小写处理
- Stop Analyzer:小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer:按照空格切分,不转小写
- Keyword Analyzer:不分词,直接将输入当作输出
- Patter Analyzer:正则表达式,默认\W+(非字符分隔)
- Language:提高了30多种常见语言的分词器
- Customer Analyzer:自定义分词器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44GET /_analyze
{
"analyzer": "standard",
"text":"Mastering Elasticsearch, elasticsearch in Action"
}
{
"tokens" : [
{
"token" : "mastering",
"start_offset" : 0,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "elasticsearch",
"start_offset" : 10,
"end_offset" : 23,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "elasticsearch",
"start_offset" : 25,
"end_offset" : 38,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "in",
"start_offset" : 39,
"end_offset" : 41,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "action",
"start_offset" : 42,
"end_offset" : 48,
"type" : "<ALPHANUM>",
"position" : 4
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
701. simple Analyzer
按照非字母切分,非字母的都被去除;小写处理
GET /_analyze
{
"analyzer": "simple",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2. Whitespace Analyzer
按照空格切分
GET /_analyze
{
"analyzer": "whitespace",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
3. Stop Analyzer
相比Simple Analyzer,多了stop filter(会把the a is等修饰词去除)
GET /_analyze
{
"analyzer": "stop",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
4. Keyword Analyzer
不分词,直接将输出当一个term输出
GET /_analyze
{
"analyzer": "keyword",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
5. Pattern Analyzer
通过正则表达式进行分词,默认\W+,非字符的符号进行分隔
GET /_analyze
{
"analyzer": "pattern",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
6. Language Analyzer
GET /_analyze
{
"analyzer": "english",
"text":"2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
7. 中文分词
中文句子:切分成一个一个词(不是一个个字);英文中:单词有自然的空格作为分隔
一句中文,在不同的上下文,有不同的理解;一些例子(他说的确实在理/这事的确定不下来)
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "这个苹果不大好吃"
}