哈希树(hash tree;Merkle tree),在密码学及计算机科学中是一种树形数据结构,每个叶节点均以数据块的哈希作为标签,而除了叶节点以外的节点则以其子节点标签的加密哈希作为标签 。哈希树能够高效、安全地验证大型数据结构的内容。哈希树的概念由瑞夫·墨克于 1979 年申请专利,故亦称墨克树(Merkle tree)。
Merkle 树的原理:
它使用的是单向哈希。哈希树的顶部为顶部哈希(top hash),亦称根哈希(root hash)或主哈希(master hash)。它是通过并联两个子哈希来往树上爬直到找到根哈希。单向哈希可以避免碰撞,而且由于它是确定性算法,因此不会也不可能存在两个一样的文本哈希。
理论基础
质数分辨定理
简单地说就是: n个不同的质数可以“分辨”的连续整数的个数和他们的乘积相等。“分辨”就是指这些连续的整数不可能有完全相同的余数序列。
在将一个数进行 Hash 的时候,对于数,当一个质数不够用的时候,可以加上第二个质数,用两个 mod 来确定该数据在库中的位置。那么这里需要简单的解释一下,对于一个质数 x,它的 mod 有 [ 0 … x - 1 ] x 种;所以对于两个质数 x 和 y,能存储的无一重复的数据有 x y 个,其实也就是开一个 xy 的二维数组。但是当数据极其多时,用两个质数去 mod 显然也是有不够的时候,就还要再加一个。
为了便于查找,选取最小的十个质数,也就是 2,3,5,7,11,13,17,23,29,31 来mod,能包括的数就有 10555815270 个,已经远超出 longint 了。
也就是说,如果我们开一个十维数组,那么取到一个数的效率就是 O( 1 )!但是那样显然太浪费空间了,就可以用到树。
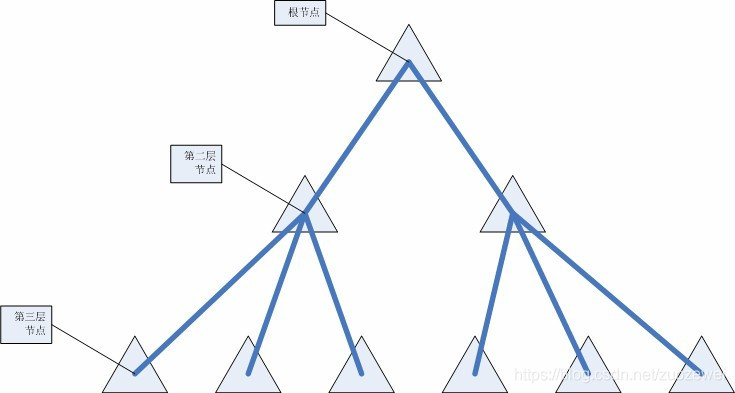
同一节点中的子节点,从左到右代表不同的余数结果。
例如:第二层节点下有三个子节点。那么从左到右分别代表:除 3 余 0,除 3 余 1 和除 3 余 2。
对质数的余数决定了处理的路径。
例如:某个数来到第二层子节点,那么它要做取余操作,然后再决定从哪个子节点向下搜寻。如果这个数是 12 那么它需要从第一个子节点向下搜索;如果这个数是7那么它需要从第二个子节点向下搜索;如果这个数是32那么它需要从第三个子节点向下搜索。
这就是一个 HashTree 了。
应用场景
- 优点
结构简单
从 HashTree 的结构来说,非常的简单。每层节点的子节点个数为连续的质数。子节点可以随时创建。因此 HashTree 的结构是动态的,也不像某些 Hash 算法那样需要长时间的初始化过程。HashTree 也没有必要为不存在的关键字提前分配空间。
需要注意的是 HashTree 是一个单向增加的结构,即随着所需要存储的数据量增加而增大。即使数据量减少到原来的数量,但是 HashTree 的总节点数不会减少。这样做的目的是为了避免结构的调整带来的额外消耗。
查找迅速
从算法过程我们可以看出,对于整数,HashTree 层级最多能增加到10。因此最多只需要十次取余和比较操作,就可以知道这个对象是否存在。这个在算法逻辑上决定了 HashTree 的优越性。
一般的树状结构,往往随着层次和层次中节点数的增加而导致更多的比较操作。操作次数可以说无法准确确定上限。而 HashTree 的查找次数和元素个数没有关系。如果元素的连续关键字总个数在计算机的整数(32bit)所能表达的最大范围内,那么比较次数就最多不会超过10次,通常低于这个数值。
结构不变
HashTree 在删除的时候,并不做任何结构调整。这个也是它的一个非常好的优点。常规树结构在增加元素和删除元素的时候都要做一定的结构调整,否则他们将可能退化为链表结构,而导致查找效率的降低。HashTree 采取的是一种“见缝插针”的算法,从来不用担心退化的问题,也不必为优化结构而采取额外的操作,因此大大节约了操作时间。
- 缺点
非排序性
HashTree 不支持排序,没有顺序特性。如果在此基础上不做任何改进的话并试图通过遍历来实现排序,那么操作效率将远远低于其他类型的数据结构。
- 应用
HashTree 可以广泛应用于那些需要对大容量数据进行快速匹配操作的地方。例如:数据库索引系统、短信息中的收条匹配、大量号码路由匹配、信息过滤匹配。HashTree 不需要额外的平衡和防止退化的操作,效率十分理想。
python实现
1 | import hashlib |
jmeter中的HashTree
构造函数
构造函数有多种形式:
HashTree(Map<Object, HashTree> _map, Object key):若 HashTree 不为空则使用 HashTree,若 key 不为空则设为 top-level(root)节点,也可能是空。这个构造函数是最为主要的构造函数,它还有几个变形体都是调用它。
1 | /** |
traverseInto
完成树遍历和执行的递归方法对 HashTreeTraverser 的回调。使用深度优先遍历 hashTree
traverse(HashTreeTraverser visitor):允许 HashTreeTraverser 接口的任何实现轻松遍历(深度优先)HashTree 的所有节点。
1 | /** |