小整数对象池
小整数[-5,257)共用对象,常驻内存
单个字符共用对象,常驻内存
1 | >> a=1 |
大整数对象池
每一个大整数,均创建一个新的对象。大整数不共用内存,引用计数为0,销毁
1 | >>> a=1234 |
intern机制
- 单个单词,不可修改,默认开启intern机制,共用对象,引用计数为0,则销毁
- 字符串(含有空格),不可修改,没开启intern机制,不共用对象,引用计数为0,销毁
- 数值类型和字符串类型在 Python 中都是不可变的,这意味着你无法修改这个对象的值,每次对变量的修改,实际上是创建一个新的对象
1 | >>> a="helloworld" |
Garbage collection(GC垃圾回收)
Python里也同java一样采用了垃圾收集机制,不过不一样的是: python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。
引用计数机制:
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
1 | typedef struct_object { |
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.
1 | #define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数 |
当引用计数为0时,该对象生命就结束了。
引用计数机制的优点:
- 简单
- 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点:
- 维护引用计数消耗资源
- 循环引用
1 | list1 = [] |
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。 对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。(标记清除和分代收集)
Python 的对象分配
用Pyhon来创建一个Node对象: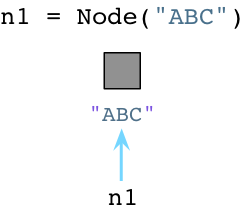
与Ruby不同,当创建对象时Python立即向操作系统请求内存。(Python实际上实现了一套自己的内存分配系统,在操作系统堆之上提供了一个抽象层。但是我今天不展开说了。)
当我们创建第二个对象的时候,再次像OS请求内存: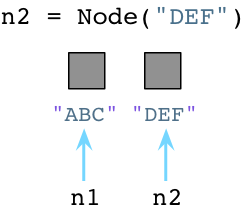
在内部,创建一个对象时,Python总是在对象的C结构体里保存一个整数,称为引用数。期初,Python将这个值设置为1: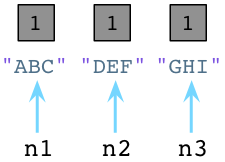
值为1说明分别有个一个指针指向或是引用这三个对象。假如我们现在创建一个新的Node实例,JKL: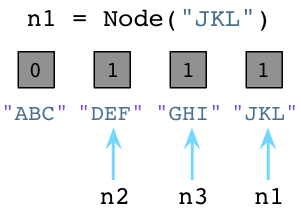
与之前一样,Python设置JKL的引用数为1。然而,请注意由于我们改变了n1指向了JKL,不再指向ABC,Python就把ABC的引用数置为0了。 此刻,Python垃圾回收器立刻挺身而出!每当对象的引用数减为0,Python立即将其释放,把内存还给操作系统:
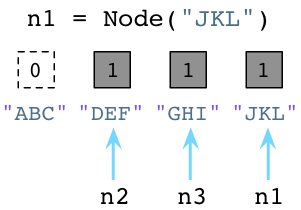
上面Python回收了ABC Node实例使用的内存。记住,Ruby弃旧对象原地于不顾,也不释放它们的内存。
Python的这种垃圾回收算法被称为引用计数。是George-Collins在1960年发明的,恰巧与John McCarthy发明的可用列表算法在同一年出现。就像Mike-Bernstein在6月份哥谭市Ruby大会杰出的垃圾回收机制演讲中说的: “1960年是垃圾收集器的黄金年代…”
现在来看第二例子。加入我们让n2引用n1: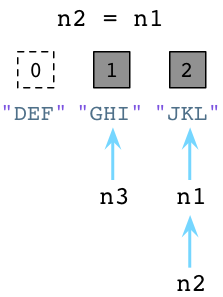
上图中左边的DEF的引用数已经被Python减少了,垃圾回收器会立即回收DEF实例。同时JKL的引用数已经变为了2 ,因为n1和n2都指向它。
标记-清除
首先Ruby把程序停下来,Ruby用”地球停转垃圾回收大法”。之后Ruby轮询所有指针,变量和代码产生别的引用对象和其他值。同时Ruby通过自身的虚拟机便利内部指针。标记出这些指针引用的每个对象。
如果说被标记的对象是存活的,剩下的未被标记的对象只能是垃圾,这意味着我们的代码不再会使用它了。我会在下图中用白格子表示垃圾对象:
接下来Ruby清除这些无用的垃圾对象,把它们送回到可用列表中: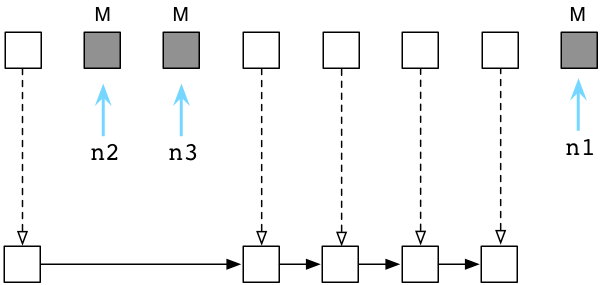
在内部这一切发生得迅雷不及掩耳,因为Ruby实际上不会吧对象从这拷贝到那。而是通过调整内部指针,将其指向一个新链表的方式,来将垃圾对象归位到可用列表中的。
Python中的零代(Generation Zero)
python使用一种不同的链表来持续追踪活跃的对象。而不将其称之为“活跃列表”,Python的内部C代码将其称为零代(Generation Zero)。每次当你创建一个对象或其他什么值的时候,Python会将其加入零代链表: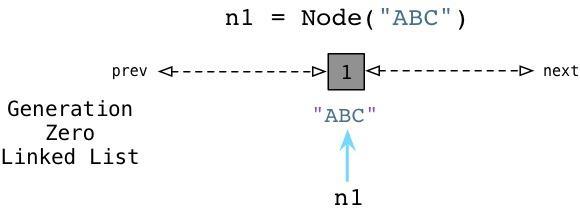
从上边可以看到当我们创建ABC节点的时候,Python将其加入零代链表。请注意到这并不是一个真正的列表,并不能直接在你的代码中访问,事实上这个链表是一个完全内部的Python运行时。 相似的,当我们创建DEF节点的时候,Python将其加入同样的链表: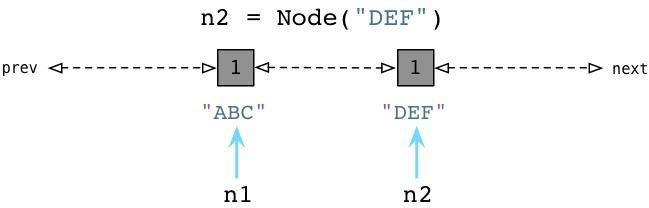
现在零代包含了两个节点对象。(他还将包含Python创建的每个其他值,与一些Python自己使用的内部值。)
检测循环引用
随后,Python会循环遍历零代列表上的每个对象,检查列表中每个互相引用的对象,根据规则减掉其引用计数。在这个过程中,Python会一个接一个的统计内部引用的数量以防过早地释放对象。
为了便于理解,来看一个例子:
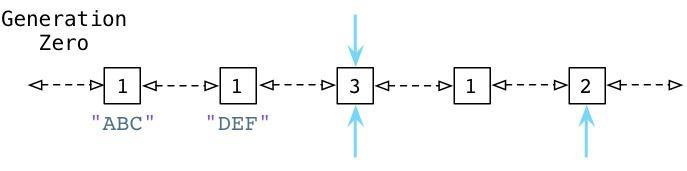
从上面可以看到 ABC 和 DEF 节点包含的引用数为1.有三个其他的对象同时存在于零代链表中,蓝色的箭头指示了有一些对象正在被零代链表之外的其他对象所引用。(接下来我们会看到,Python中同时存在另外两个分别被称为一代和二代的链表)。这些对象有着更高的引用计数因为它们正在被其他指针所指向着。
接下来你会看到Python的GC是如何处理零代链表的
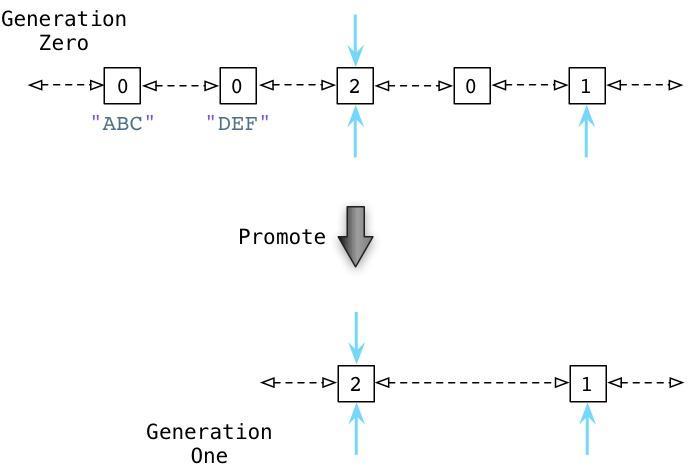
通过识别内部引用,Python能够减少许多零代链表对象的引用计数。在上图的第一行中你能够看见ABC和DEF的引用计数已经变为零了,这意味着收集器可以释放它们并回收内存空间了。剩下的活跃的对象则被移动到一个新的链表:一代链表。
从某种意义上说,Python的GC算法类似于Ruby所用的标记回收算法。周期性地从一个对象到另一个对象追踪引用以确定对象是否还是活跃的,正在被程序所使用的,这正类似于Ruby的标记过程。
Python中的GC阈值
Python什么时候会进行这个标记过程?随着你的程序运行,Python解释器保持对新创建的对象,以及因为引用计数为零而被释放掉的对象的追踪。从理论上说,这两个值应该保持一致,因为程序新建的每个对象都应该最终被释放掉。
当然,事实并非如此。因为循环引用的原因,并且因为你的程序使用了一些比其他对象存在时间更长的对象,从而被分配对象的计数值与被释放对象的计数值之间的差异在逐渐增长。一旦这个差异累计超过某个阈值,则Python的收集机制就启动了,并且触发上边所说到的零代算法,释放“浮动的垃圾”,并且将剩下的对象移动到一代列表。
随着时间的推移,程序所使用的对象逐渐从零代列表移动到一代列表。而Python对于一代列表中对象的处理遵循同样的方法,一旦被分配计数值与被释放计数值累计到达一定阈值,Python会将剩下的活跃对象移动到二代列表。
通过这种方法,你的代码所长期使用的对象,那些你的代码持续访问的活跃对象,会从零代链表转移到一代再转移到二代。通过不同的阈值设置,Python可以在不同的时间间隔处理这些对象。Python处理零代最为频繁,其次是一代然后才是二代。
gc模块常用功能解析
gc模块提供一个接口给开发者设置垃圾回收的选项。上面说到,采用引用计数的方法管理内存的一个缺陷是循环引用,而gc模块的一个主要功能就是解决循环引用的问题。
常用函数:
- gc.set_debug(flags) 设置gc的debug日志,一般设置为gc.DEBUG_LEAK
- gc.collect([generation]) 显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,1代表检查一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,执行一个full collection,也就是等于传2。 返回不可达(unreachable objects)对象的数目
- gc.get_threshold() 获取的gc模块中自动执行垃圾回收的频率。
- gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置自动执行垃圾回收的频率。
- gc.get_count() 获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
gc模块的自动垃圾回收机制
必须要import gc模块,并且is_enable()=True才会启动自动垃圾回收。
这个机制的主要作用就是发现并处理不可达的垃圾对象。
1 | 垃圾回收=垃圾检查+垃圾回收 |
在Python中,采用分代收集的方法。把对象分为三代,一开始,对象在创建的时候,放在一代中,如果在一次一代的垃圾检查中,改对象存活下来,就会被放到二代中,同理在一次二代的垃圾检查中,该对象存活下来,就会被放到三代中。
gc模块里面会有一个长度为3的列表的计数器,可以通过gc.get_count()获取。
例如(488,3,0),其中488是指距离上一次一代垃圾检查,Python分配内存的数目减去释放内存的数目,注意是内存分配,而不是引用计数的增加。例如:
1 | print gc.get_count() # (590, 8, 0) |
3是指距离上一次二代垃圾检查,一代垃圾检查的次数,同理,0是指距离上一次三代垃圾检查,二代垃圾检查的次数。
gc模快有一个自动垃圾回收的阀值,即通过gc.get_threshold函数获取到的长度为3的元组,例如(700,10,10) 每一次计数器的增加,gc模块就会检查增加后的计数是否达到阀值的数目,如果是,就会执行对应的代数的垃圾检查,然后重置计数器
例如,假设阀值是(700,10,10):
1 | 当计数器从(699,3,0)增加到(700,3,0),gc模块就会执行gc.collect(0),即检查一代对象的垃圾,并重置计数器为(0,4,0) |
gc模块唯一处理不了的是循环引用的类都有del方法,所以项目中要避免定义del方法
小结
垃圾回收机制
Python中的垃圾回收是以引用计数为主,分代收集为辅。
导致引用计数+1的情况
- 对象被创建,例如a=23
- 对象被引用,例如b=a
- 对象被作为参数,传入到一个函数中,例如func(a)
- 对象作为一个元素,存储在容器中,例如list1=[a,a]
导致引用计数-1的情况
- 对象的别名被显式销毁,例如del a
- 对象的别名被赋予新的对象,例如a=24
- 一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量(全局变量不会)
- 对象所在的容器被销毁,或从容器中删除对象
查看一个对象的引用计数
1 | import sys |
可以查看a对象的引用计数,但是比正常计数大1,因为调用函数的时候传入a,这会让a的引用计数+1
循环引用导致内存泄露
1 | class ClassA(): |
执行f2(),进程占用的内存会不断增大。
- 创建了c1,c2后这两块内存的引用计数都是1,执行c1.t=c2和c2.t=c1后,这两块内存的引用计数变成2.
- 在del c1后,内存1的对象的引用计数变为1,由于不是为0,所以内存1的对象不会被销毁,所以内存2的对象的引用数依然是2,在del c2后,同理,内存1的对象,内存2的对象的引用数都是1。
- 虽然它们两个的对象都是可以被销毁的,但是由于循环引用,导致垃圾回收器都不会回收它们,所以就会导致内存泄露。
垃圾回收
有三种情况会触发垃圾回收
- 调用gc.collect(),
- 当gc模块的计数器达到阀值的时候。
- 程序退出的时候
1 | #coding=utf-8 |
说明:
- 圾回收后的对象会放在gc.garbage列表里面
- gc.collect()会返回不可达的对象数目,4等于两个对象以及它们对应的dict