单线程
1 | def say_hello(name): |
多线程
1 | import threading |
查看线程数量
1 | import threading |
线程执行代码的封装
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,所以使用threading模块时,往往会定义一个新的子类class,只要继承threading.Thread就可以了,然后重写run方法.
1 | class MyThread(threading.Thread): |
python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
1 | class MyThread(threading.Thread): |
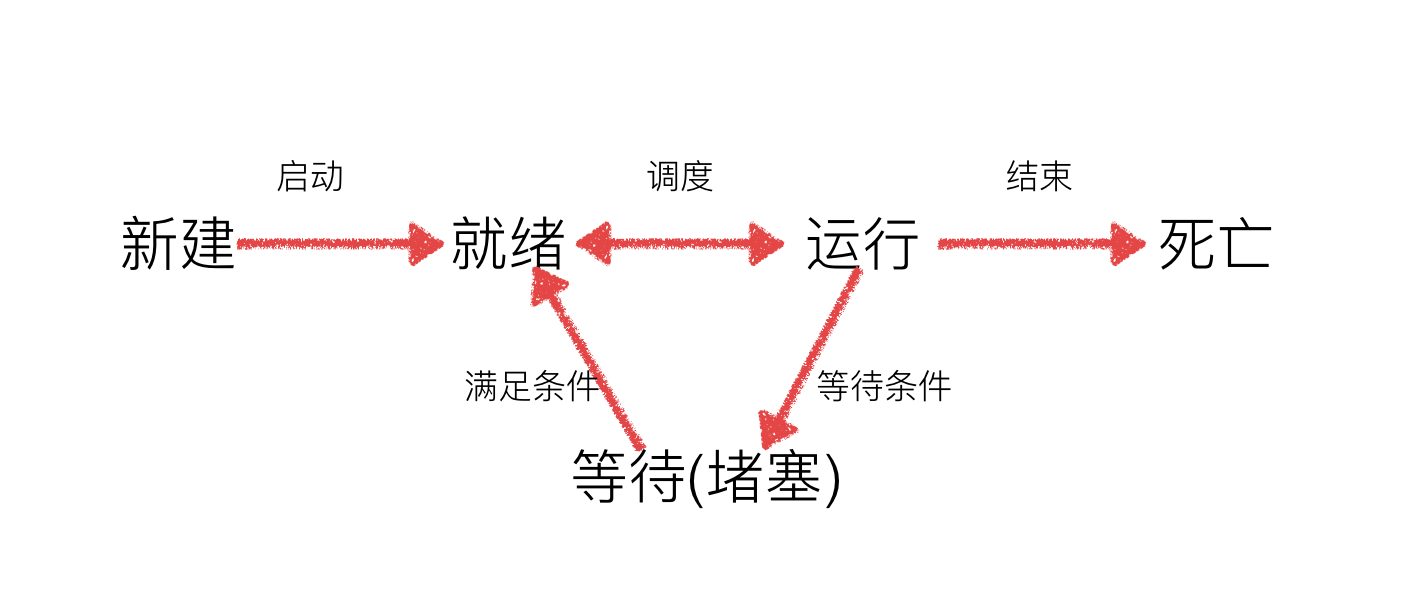
从代码和执行结果我们可以看出,多线程程序的执行顺序是不确定的。当执行到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。上面的代码中只能保证每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
- 每个线程一定会有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
- 当线程的run()方法结束时该线程完成。
- 无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
- 线程的几种状态
多线程-共享全局变量
1 | num = 1 |
同步
多线程开发可能遇到的问题
假设两个线程t1和t2都要对num=0进行增1运算,t1和t2都各对num修改10次,num的最终的结果应该为20。
但是由于是多线程访问,有可能出现下面情况:
在num=0时,t1取得num=0。此时系统把t1调度为”sleeping”状态,把t2转换为”running”状态,t2也获得num=0。然后t2对得到的值进行加1并赋给num,使得num=1。然后系统又把t2调度为”sleeping”,把t1转为”running”。线程t1又把它之前得到的0加1后赋值给num。这样,明明t1和t2都完成了1次加1工作,但结果仍然是num=1。
什么是同步
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B依言执行,再将结果给A;A再继续操作。
解决问题的思路
- 系统调用t1,然后获取到num的值为0,此时上一把锁,即不允许其他现在操作num
- 对num的值进行+1
- 解锁,此时num的值为1,其他的线程就可以使用num了,而且是num的值不是0而是1
- 同理其他线程在对num进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性
1 | import threading |
问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期。这种现象称为“线程不安全”。
互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定。
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。1
2
3
4
5
6#创建锁
mutex = threading.Lock()
#锁定
mutex.acquire([blocking])
#释放
mutex.release()
其中,锁定方法acquire可以有一个blocking参数。
- 如果设定blocking为True,则当前线程会堵塞,直到获取到这个锁为止(如果没有指定,那么默认为True)
- 如果设定blocking为False,则当前线程不会堵塞
1 | import threading |
上锁解锁过程
当一个线程调用锁的acquire()方法获得锁时,锁就进入“locked”状态。
每次只有一个线程可以获得锁。如果此时另一个线程试图获得这个锁,该线程就会变为“blocked”状态,称为“阻塞”,直到拥有锁的线程调用锁的release()方法释放锁之后,锁进入“unlocked”状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
优势和劣势对比
锁的好处:
确保了某段关键代码只能由一个线程从头到尾完整地执行
锁的坏处:
阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了
由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁
多线程-非共享数据
在多线程开发中,全局变量是多个线程都共享的数据,而局部变量等是各自线程的,是非共享的
1 | import threading |
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
1 | import threading |
同步应用
可以使用互斥锁完成多个任务,有序的进程工作,这就是线程的同步
1 | import threading |
线程同步之条件变量
互斥锁是最简单的线程同步机制,Python提供的Condition对象提供了对复杂线程同步问题的支持。
Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,还提供了wait和notify方法。
线程首先acquire一个条件变量,然后判断一些条件。
- 如果条件不满足则wait;
- 如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件。不断的重复这一过程,从而解决复杂的同步问题。
1 | from click._compat import raw_input |
可以认为Condition对象维护了一个锁(Lock/RLock)和一个waiting池。线程通过acquire获得Condition对象,当调用wait方法时,线程会释放Condition内部的锁并进入blocked状态,同时在waiting池中记录这个线程。当调用notify方法时,Condition对象会从waiting池中挑选一个线程,通知其调用acquire方法尝试取到锁。
Condition对象的构造函数可以接受一个Lock/RLock对象作为参数,如果没有指定,则Condition对象会在内部自行创建一个RLock。
除了notify方法外,Condition对象还提供了notifyAll方法,可以通知waiting池中的所有线程尝试acquire内部锁。由于上述机制,处于waiting状态的线程只能通过notify方法唤醒,所以notifyAll的作用在于防止有线程永远处于沉默状态。
生产者与消费者-条件变量
1 | import threading |
ThreadLocal
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
1 | import threading |
线程池
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
线程池的基类是 concurrent.futures 模块中的 Executor,Executor 提供了两个子类,即 ThreadPoolExecutor 和 ProcessPoolExecutor,其中 ThreadPoolExecutor 用于创建线程池,而 ProcessPoolExecutor 用于创建进程池。
如果使用线程池/进程池来管理并发编程,那么只要将相应的 task 函数提交给线程池/进程池,剩下的事情就由线程池/进程池来搞定。
Executor 提供了如下常用方法:
- submit(fn, args, **kwargs):将 fn 函数提交给线程池。args 代表传给 fn 函数的参数,*kwargs 代表以关键字参数的形式为 fn 函数传入参数。
- map(func, iterables, timeout=None, chunksize=1):该函数类似于全局函数 map(func, iterables),只是该函数将会启动多个线程,以异步方式立即对 iterables 执行 map 处理。
- shutdown(wait=True):关闭线程池。
程序将 task 函数提交(submit)给线程池后,submit 方法会返回一个 Future 对象,Future 类主要用于获取线程任务函数的返回值。由于线程任务会在新线程中以异步方式执行,因此,线程执行的函数相当于一个“将来完成”的任务,所以 Python 使用 Future 来代表。
Future 提供了如下方法:
1 | cancel():取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。 |
在用完一个线程池后,应该调用该线程池的 shutdown() 方法,该方法将启动线程池的关闭序列。调用 shutdown() 方法后的线程池不再接收新任务,但会将以前所有的已提交任务执行完成。当线程池中的所有任务都执行完成后,该线程池中的所有线程都会死亡。
使用线程池来执行线程任务的步骤如下:
- 调用 ThreadPoolExecutor 类的构造器创建一个线程池。
- 定义一个普通函数作为线程任务。
- 调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。
- 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
1 | from concurrent.futures import ThreadPoolExecutor |
如果程序不希望直接调用 result() 方法阻塞线程,则可通过 Future 的 add_done_callback() 方法来添加回调函数,该回调函数形如 fn(future)。当线程任务完成后,程序会自动触发该回调函数,并将对应的 Future 对象作为参数传给该回调函数。
1 | from concurrent.futures import ThreadPoolExecutor |
此外,Exectuor 还提供了一个 map(func, *iterables, timeout=None, chunksize=1) 方法,该方法的功能类似于全局函数 map(),区别在于线程池的 map() 方法会为 iterables 的每个元素启动一个线程,以并发方式来执行 func 函数。这种方式相当于启动 len(iterables) 个线程,井收集每个线程的执行结果。
1 | from concurrent.futures import ThreadPoolExecutor |