锁的类型
mysql锁分为共享锁和排他锁,也叫做读锁和写锁。
读锁是共享的,可以通过lock in share mode实现,这时候只能读不能写。
写锁是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和⾏锁两种。
表锁会锁定整张表并且阻塞其他⽤户对该表的所有读写操作,⽐如alter修改表结构的时候会锁表。
⾏锁⼜可以分为乐观锁和悲观锁,悲观锁可以通过for update实现,乐观锁则通过版本号实现。
mysql 排它锁之行锁、间隙锁、后码锁
MySQL InnoDB支持三种行锁定
- 行锁(Record Lock):锁直接加在索引记录上面,锁住的是key。
- 间隙锁(Gap Lock):锁定索引记录间隙,确保索引记录的间隙不变。间隙锁是针对事务隔离级别为可重复读或以上级别而设计的。
- 后码锁(Next-Key Lock):行锁和间隙锁组合起来就叫Next-Key Lock。
默认情况下,InnoDB工作在可重复读隔离级别下,并且会以Next-Key Lock的方式对数据行进行加锁,这样可以有效防止幻读的发生。Next-Key Lock是行锁和间隙锁的组合,当InnoDB扫描索引记录的时候,会首先对索引记录加上行锁(Record Lock),再对索引记录两边的间隙加上间隙锁(Gap Lock)。加上间隙锁之后,其他事务就不能在这个间隙修改或者插入记录。
行锁(Record Lock)
- 当需要对表中的某条数据进行写操作(insert、update、delete、select for update)时,需要先获取记录的排他锁(X锁),这个就称为行锁。
1 | create table x(`id` int, `num` int, index `idx_id` (`id`)); |
- 针对InnoDB RR隔离级别,上述SQL示例展示了行锁的特点:“锁定特定行不允许进行修改”,但行锁是基于表索引的,如果where条件中用的是num字段(非索引列)将产生不一样的现象:
1 | -- 事务A |
Gap锁(Gap Lock)
在MySQL中select称为快照读,不需要锁,而insert、update、delete、select for update则称为当前读,需要给数据加锁,幻读中的“读”即是针对当前读。
RR事务隔离级别允许存在幻读,但InnoDB RR级别却通过Gap锁避免了幻读
产生间隙锁的条件(RR事务隔离级别下)
- 使用普通索引锁定
- 使用多列唯一索引
- 使用唯一索引锁定多行记录
唯一索引的间隙锁
1 | 测试环境 |
以上数据,会生成隐藏间隙
1 | (-infinity, 1] (1, 5] (5, 7] (7, 11] (11, +infinity] |
只使用记录锁,不会产生间隙锁
1 | /* 开启事务1 */ |
以上,由于主键是唯一索引,而且是只使用一个索引查询,并且只锁定一条记录,所以,只会对 id = 5 的数据加上记录锁,而不会产生间隙锁。
产生间隙锁
1 | /* 开启事务1 */ |
从上面我们可以看到,(5, 7]、(7, 11] 这两个区间,都不可插入数据,其它区间,都可以正常插入数据。所以当我们给 (5, 7] 这个区间加锁的时候,会锁住 (5, 7]、(7, 11] 这两个区间。
锁住不存在的数据
1 | /* 开启事务1 */ |
我们可以看出,指定查询某一条记录时,如果这条记录不存在,会产生间隙锁
结论
- 对于指定查询某一条记录的加锁语句,如果该记录不存在,会产生记录锁和间隙锁,如果记录存在,则只会产生记录锁,如:WHERE id = 5 FOR UPDATE;
- 对于查找某一范围内的查询语句,会产生间隙锁,如:WHERE id BETWEEN 5 AND 7 FOR UPDATE;
普通索引的间隙锁
1 | CREATE TABLE `test1` ( |
执行以下的事务(事务1最后提交)
1 | /* 开启事务1 */ |
这里可以看到,number (1 - 8) 的间隙中,插入语句都被阻塞了,而不在这个范围内的语句,正常执行,这就是因为有间隙锁的原因。
结论
- 在普通索引列上,不管是何种查询,只要加锁,都会产生间隙锁,这跟唯一索引不一样
- 在普通索引跟唯一索引中,数据间隙的分析,数据行是优先根据普通索引排序,再根据唯一索引排序
ACID靠什么保证
A原⼦性由undo log⽇志保证,它记录了需要回滚的⽇志信息,事务回滚时撤销已经执⾏成功的sql
C⼀致性⼀般由代码层⾯来保证
I隔离性由MVCC来保证
D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
分表后的ID怎么保证唯⼀性
因为我们主键默认都是⾃增的,那么分表之后的主键在不同表就肯定会有冲突了。有⼏个办法考虑:
- 设定步⻓,⽐如1-1024张表我们设定1024的基础步⻓,这样主键落到不同的表就不会冲突了。
- 分布式ID,⾃⼰实现⼀套分布式ID⽣成算法或者使⽤开源的⽐如雪花算法这种
- 分表后不使⽤主键作为查询依据,⽽是每张表单独新增⼀个字段作为唯⼀主键使⽤,⽐如订单表订单号是唯⼀的,不管最终落在哪张表都基于订单号作为查询依据,更新也⼀样。
分表后⾮sharding_key的查询
可以做⼀个mapping表,⽐如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不能扫全表吧?所以我们可以做⼀个映射关系表,保存商家和⽤户的关系,查询的时候先通过商家查询到⽤户列表,再通过user_id去查询。
打宽表,⼀般⽽⾔,商户端对数据实时性要求并不是很⾼,⽐如查询订单列表,可以把订单表同步到离线(实时)数仓,再基于数仓去做成⼀张宽表,再基于其他如es提供查询服务。
数据量不是很⼤的话,⽐如后台的⼀些查询之类的,也可以通过多线程扫表,然后再聚合结果的⽅式来做。或者异步的形式也是可以的。
mysql主从同步
- master提交完事务后,写⼊binlog
- slave连接到master,获取binlog
- master创建dump线程,推送binglog到slave
- slave启动⼀个IO线程读取同步过来的master的binlog,记录到relay log中继⽇志中
- slave再开启⼀个sql线程读取relay log事件并在slave执⾏,完成同步
- slave记录⾃⼰的binglog
由于mysql默认的复制⽅式是异步的,主库把⽇志发送给从库后不关⼼从库是否已经处理,这样会产⽣⼀个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,⽇志就丢失了。由此产⽣两个概念。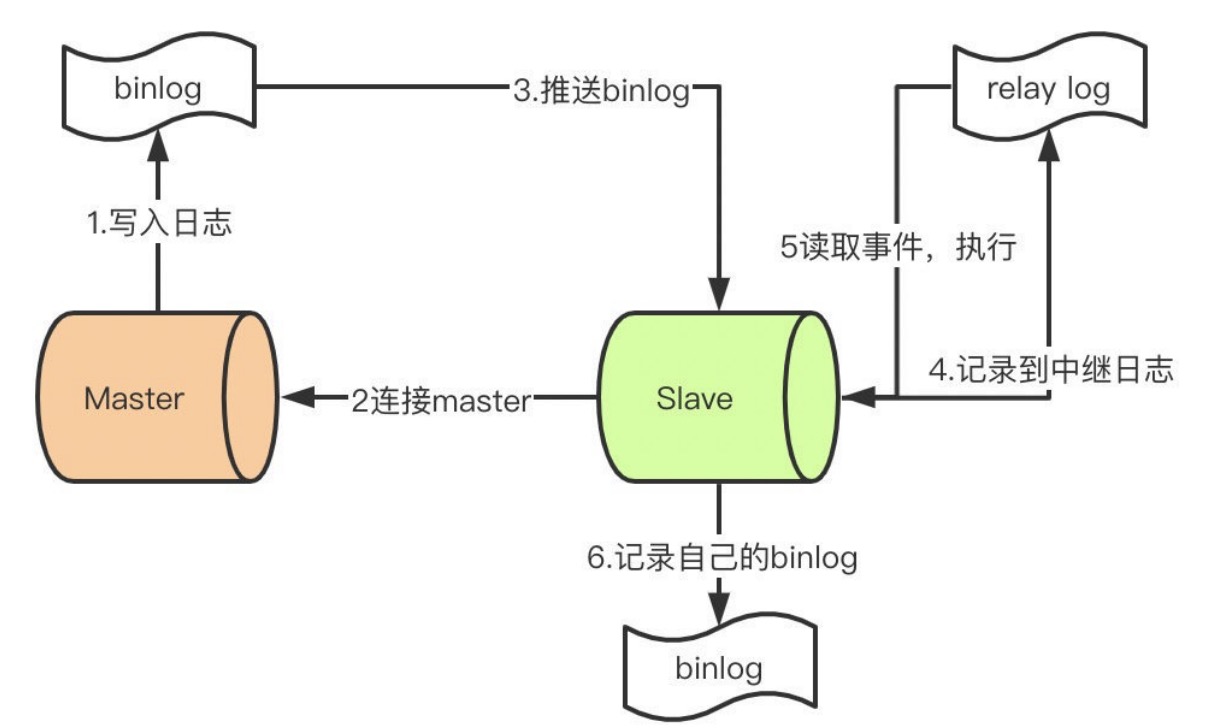
全同步复制
主库写⼊binlog后强制同步⽇志到从库,所有的从库都执⾏完成后才返回给客户端,但是很显然这个⽅式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写⼊⽇志成功后返回ACK确认给主库,主库收到⾄少⼀个从库的确认就认为写操作完成。
那主从的延迟怎么解决呢?
- 针对特定的业务场景,读写请求都强制⾛主库
- 读请求⾛从库,如果没有数据,去主库做⼆次查询