Redis的过期策略
redis主要有2种过期删除策略
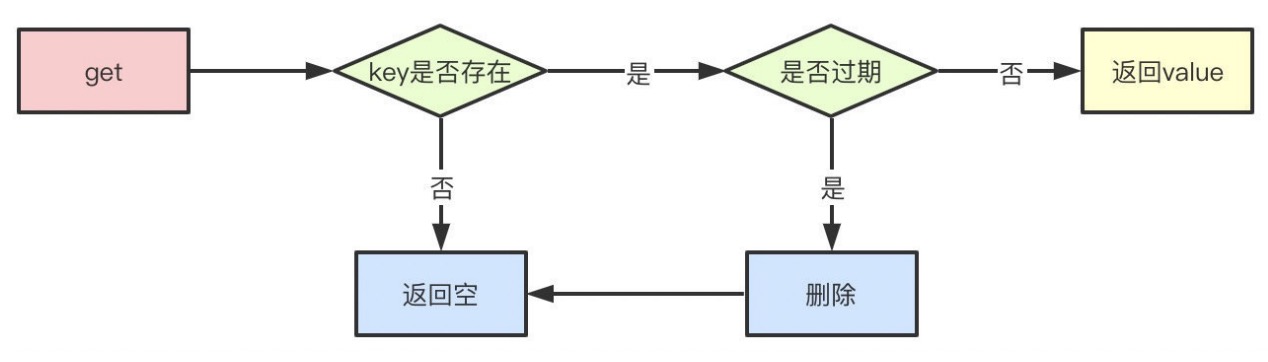
惰性删除
惰性删除指的是当我们查询key的时候才对key进⾏检测,如果已经达到过期时间,则删除。显然,他有⼀个缺点就是如果这些过期的key没有被访问,那么他就⼀直⽆法被删除,⽽且⼀直占⽤内存。
定期删除
定期删除指的是redis每隔⼀段时间对数据库做⼀次检查,删除⾥⾯的过期key。由于不可能对所有key去做轮询来删除,所以redis会每次随机取⼀些key去做检查和删除。
那么定期+惰性都没有删除过期的key怎么办?
假设redis每次定期随机查询key的时候没有删掉,这些key也没有做查询的话,就会导致这些key⼀直保存在redis⾥⾯⽆法被删除,这时候就会⾛到redis的内存淘汰机制。
- volatile-lru:从已设置过期时间的key中,移出最近最少使⽤的key进⾏淘汰
- volatile-ttl:从已设置过期时间的key中,移出将要过期的key
- volatile-random:从已设置过期时间的key中随机选择key淘汰
- allkeys-lru:从key中选择最近最少使⽤的进⾏淘汰
- allkeys-random:从key中随机选择key进⾏淘汰
- noeviction:当内存达到阈值的时候,新写⼊操作报错
Redis事务机制
redis通过MULTI、EXEC、WATCH等命令来实现事务机制,事务执⾏过程将⼀系列多个命令按照顺序⼀次性执⾏,并且在执⾏期间,事务不会被中断,也不会去执⾏客户端的其他请求,直到所有命令执⾏完毕。事务的执⾏过程如下:
- 服务端收到客户端请求,事务以MULTI开始
- 如果客户端正处于事务状态,则会把事务放⼊队列同时返回给客户端QUEUED,反之则直接执⾏这个命令
- 当收到客户端EXEC命令时,WATCH命令监视整个事务中的key是否有被修改,如果有则返回空回复到客户端表示失败,否则redis会遍历整个事务队列,执⾏队列中保存的所有命令,最后返回结果给客户端
WATCH的机制本身是⼀个CAS的机制,被监视的key会被保存到⼀个链表中,如果某个key被修改,那么REDIS_DIRTY_CAS标志将会被打开,这时服务器会拒绝执⾏事务。
Redis主从
主从架构
主从模式是最简单的实现⾼可⽤的⽅案,核⼼就是主从同步。主从同步的原理如下:
- slave发送sync命令到master
- master收到sync之后,执⾏bgsave,⽣成RDB全量⽂件
- master把slave的写命令记录到缓存
- bgsave执⾏完毕之后,发送RDB⽂件到slave,slave执⾏
- master发送缓存中的写命令到slave,slave执⾏
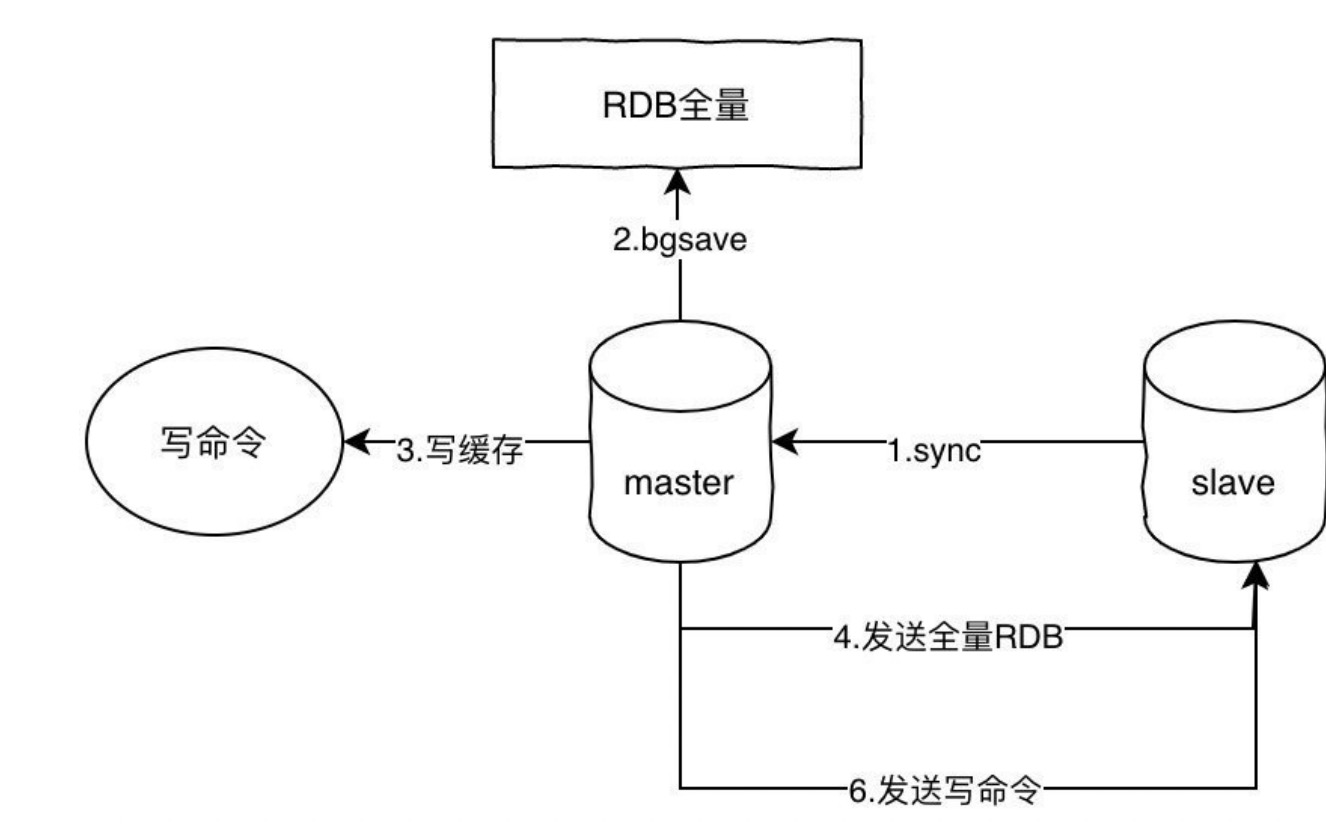
这⾥我写的这个命令是sync,但是在redis2.8版本之后已经使⽤psync来替代sync了,原因是sync命令⾮常消耗系统资源,⽽psync的效率更⾼。
哨兵
基于主从⽅案的缺点还是很明显的,假设master宕机,那么就不能写⼊数据,那么slave也就失去了作⽤,整个架构就不可⽤了,除⾮你⼿动切换,主要原因就是因为没有⾃动故障转移机制。⽽哨兵(sentinel)的功能⽐单纯的主从架构全⾯的多了,它具备⾃动故障转移、集群监控、消息通知等功能。
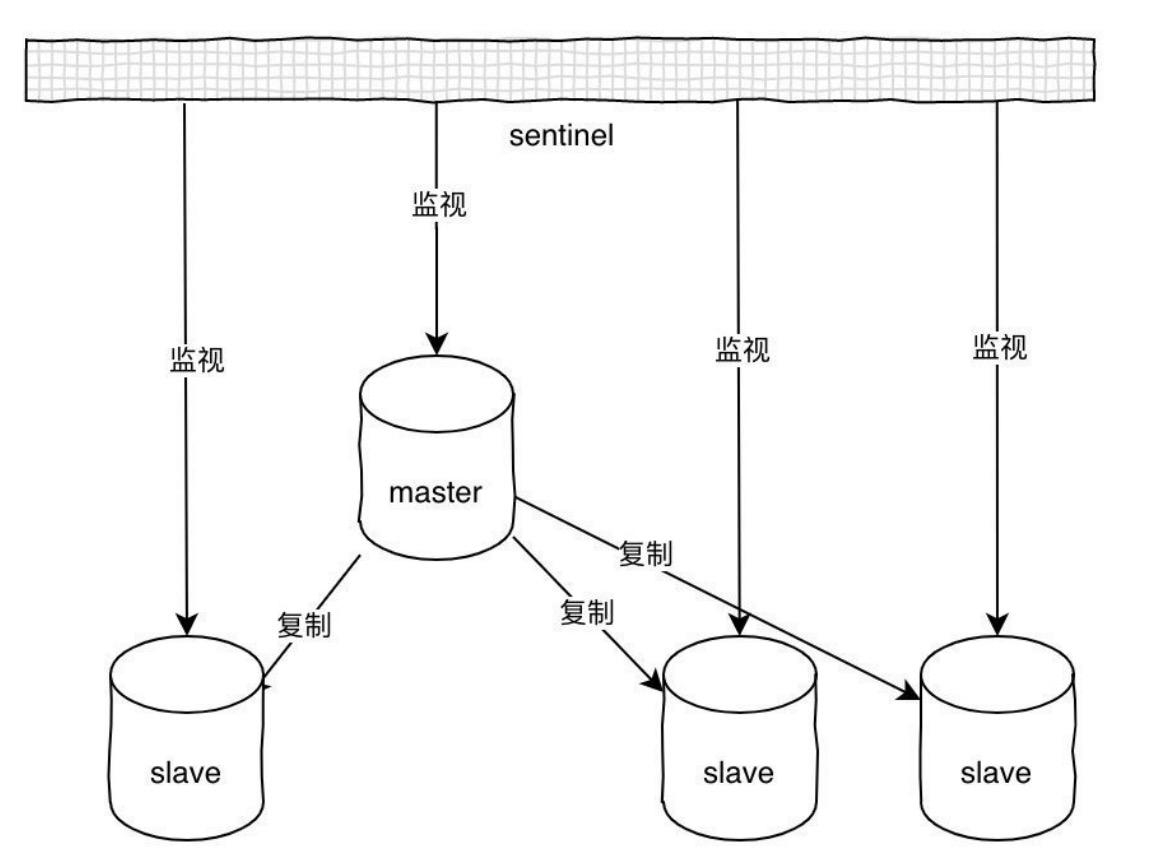
哨兵可以同时监视多个主从服务器,并且在被监视的master下线时,⾃动将某个slave提升为master,
然后由新的master继续接收命令。整个过程如下:
- 初始化sentinel,将普通的redis代码替换成sentinel专⽤代码
- 初始化masters字典和服务器信息,服务器信息主要保存ip:port,并记录实例的地址和ID
- 创建和master的两个连接,命令连接和订阅连接,并且订阅sentinel:hello频道
- 每隔10秒向master发送info命令,获取master和它下⾯所有slave的当前信息
- 当发现master有新的slave之后,sentinel和新的slave同样建⽴两个连接,同时每个10秒发送info命令,更新master信息
- sentinel每隔1秒向所有服务器发送ping命令,如果某台服务器在配置的响应时间内连续返回⽆效回复,将会被标记为下线状态
- 选举出领头sentinel,领头sentinel需要半数以上的sentinel同意
- 领头sentinel从已下线的的master所有slave中挑选⼀个,将其转换为master
- 让所有的slave改为从新的master复制数据
- 将原来的master设置为新的master的从服务器,当原来master重新回复连接时,就变成了新master的从服务器
sentinel会每隔1秒向所有实例(包括主从服务器和其他sentinel)发送ping命令,并且根据回复判断是否已经下线,这种⽅式叫做主观下线。当判断为主观下线时,就会向其他监视的sentinel询问,如果超过半数的投票认为已经是下线状态,则会标记为客观下线状态,同时触发故障转移。
redis 分片
节点
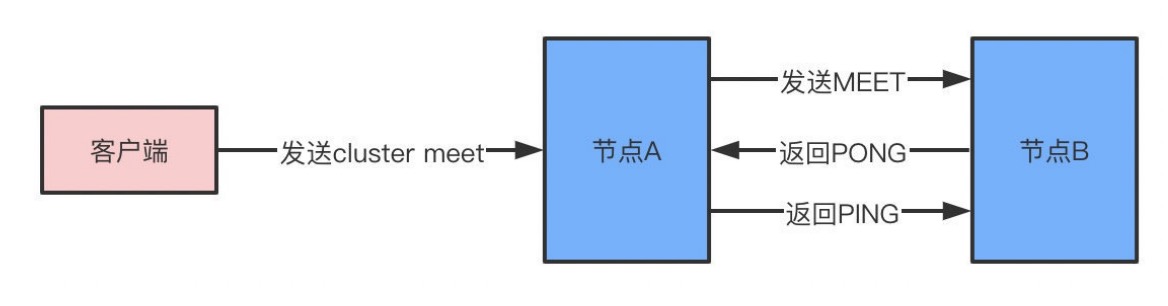
⼀个redis集群由多个节点node组成,⽽多个node之间通过cluster meet命令来进⾏连接,节点的握⼿
过程:
- 节点A收到客户端的cluster meet命令
- A根据收到的IP地址和端⼝号,向B发送⼀条meet消息
- 节点B收到meet消息返回pong
- A知道B收到了meet消息,返回⼀条ping消息,握⼿成功
- 最后,节点A将会通过gossip协议把节点B的信息传播给集群中的其他节点,其他节点也将和B进⾏握⼿
槽slot
redis通过集群分⽚的形式来保存数据,整个集群数据库被分为16384个slot,集群中的每个节点可以处理0-16384个slot,当数据库16384个slot都有节点在处理时,集群处于上线状态,反之只要有⼀个slot没有得到处理都会处理下线状态。通过cluster addslots命令可以将slot指派给对应节点处理。
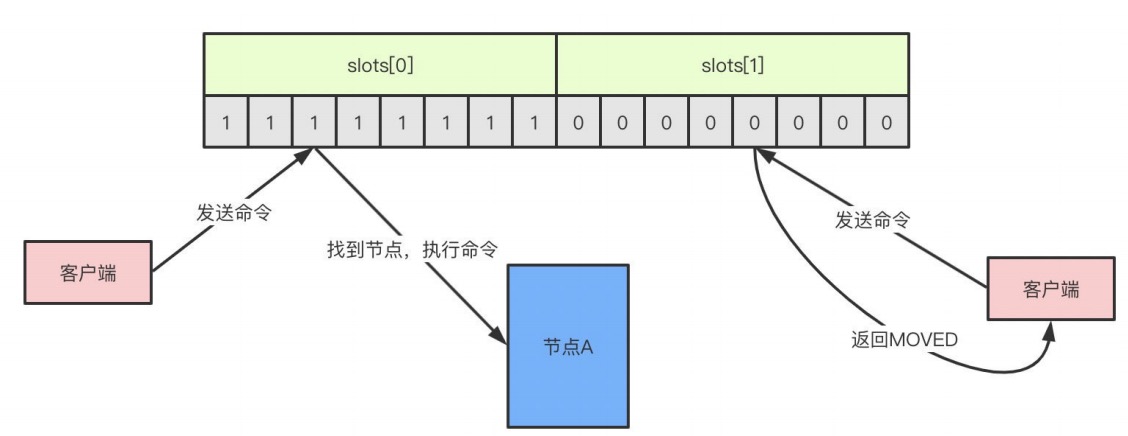
slot是⼀个位数组,数组的⻓度是16384/8=2048,⽽数组的每⼀位⽤1表示被节点处理,0表示不处理,如图所示的话表示A节点处理0-7的slot。

当客户端向节点发送命令,如果刚好找到slot属于当前节点,那么节点就执⾏命令,反之,则会返回⼀个MOVED命令到客户端指引客户端转向正确的节点。(MOVED过程是⾃动的)
如果增加或者移出节点,对于slot的重新分配也是⾮常⽅便的,redis提供了⼯具帮助实现slot的迁移,整个过程是完全在线的,不需要停⽌服务。
故障转移
如果节点A向节点B发送ping消息,节点B没有在规定的时间内响应pong,那么节点A会标记节点B为pfail疑似下线状态,同时把B的状态通过消息的形式发送给其他节点,如果超过半数以上的节点都标记B为pfail状态,B就会被标记为fail下线状态,此时将会发⽣故障转移,优先从复制数据较多的从节点选择⼀个成为主节点,并且接管下线节点的slot,整个过程和哨兵⾮常类似,都是基于Raft协议做选举。