由于uWGSI使用的是GPL2开源协议,Gunicorn使用的是MIT协议,商业使用为了规避相关法律风险,业务上有打算把uWSGI替换成Gunicorn,小结下两种组件的使用及区别。
简介
相同点
perfork是一种服务端编程模型, Nginx, Gunicorn, uWSGI都是这种模型的实现, 简单的说perfok就是master进程启动注册一堆信号处理函数, 创建listen socket fd, fork出多个worker子进程, 子进程执行accept循环处理请求(这里简化模型, 当然也可以用select, epoll多路复用), master进程只负责监控worker进程状态, 通过pipeline通信来控制worker进程.
perfork模型使用master进程来监控worker进程状态, 避免了我们使用supervisor来监控进程, 还支持多种信号来控制worker的数量, 使得CPU能充分得到利用, 多个worker进程监听同一端口, 可以配置reuse_port参数在worker进程间负载均衡.
区别
Gunicorn
Gunicorn是使用Python实现的WSGI服务器, 直接提供了http服务, 并且在woker上提供了多种选择, gevent, eventlet这些都支持, 在多worker最大化里用CPU的同时, 还可以使用协程来提供并发支撑, 对于网络IO密集的服务比较有利.
同时Gunicorn也很容易就改造成一个TCP的服务, 比如doge重写worker类, 在针对长连接的服务时, 最好开启reuse_port, 避免worker进程负载不均。
uWSGI
不同于Gunicorn, uWSGI是使用C写的, 它的socket fd创建, worker进程的启动都是使用C语言系统接口来实现的, 在worker进程处理循环中, 解析了http请求后, 使用python的C接口生成environ对象, 再把这个对象作为参数塞到暴露出来的WSGI application函数中调用. 而这一切都是在C程序中进行, 只是在处理请求的时候交给python虚拟机调用application. 完全使用C语言实现的好处是性能会好一些.
除了支持http协议, uWSGI还实现了uwsgi协议, 一般我们会在uWSGI服务器前面使用Nginx作为负载均衡, 如果使用http协议, 请求在转发到uWSGI前已经在Nginx这里解析了一遍, 转发到uWSGI又会重新解析一遍. uWSGI为了追求性能, 设计了uwsgi协议, 在Nginx解析完以后直接把解析好的结果通过uwsgi协议转发到uWSGI服务器, uWSGI拿到请求按格式生成environ对象, 不需要重复解析请求. 如果用Nginx配合uWSGI, 最好使用uwsgi协议来转发请求.
除了是一个WSGI服务器, uWSGI还是一个开发框架, 它提供了缓存, 队列, rpc等等功能, 在github找找就会发现有人用它的缓存写了一个Django cache backend, 用它的队列实现异步任务这些东西, 但是用了这些东西技术栈也就跟uWSGI绑定在一起, 所以一般也只是把uWSGI当作WSGI服务器来用。
测试对比
组里其他同学测试简单测试如下:
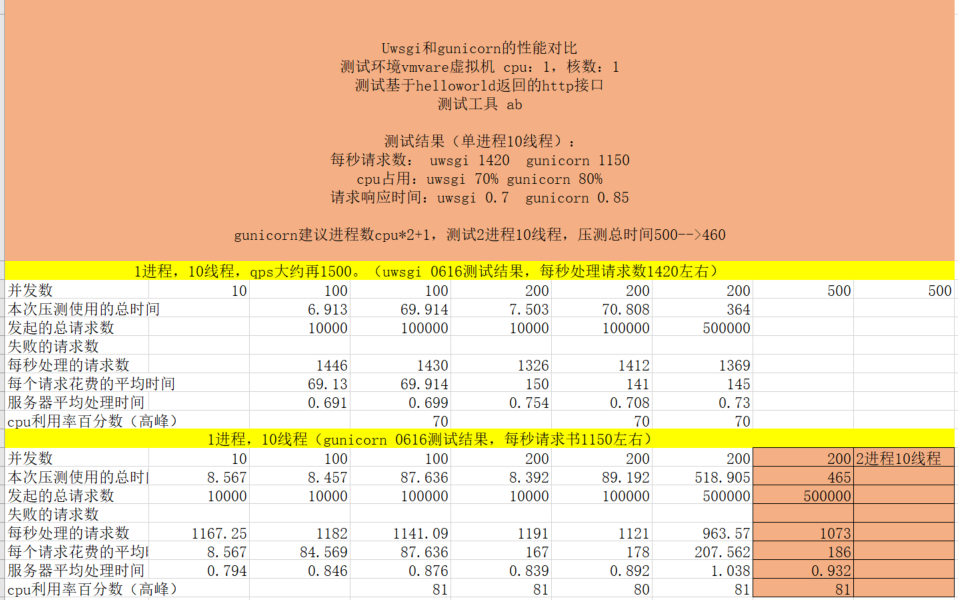
与http://www.zh-noone.cn/2019/11/gunicorn-uwsgi%E6%80%A7%E8%83%BD%E5%AF%B9%E6%AF%94/ 文章中测试结果大体一致。其中该文章中总结使用方式如下:
gunicorn小结
1 | werkzeug:RPS:681.30/sec |
uwsgi小结
1 | 打印日志:RPS:1605.11/sec |
小结
1 | gunicorn 最好使用eventlet(非preload模式) |
Gunicorn简介
Gunicorn,是一个针对Python的、在Unix系统上运行的、用来解析HTTP请求的网关服务。它的特点是:能和大多数的Python web框架兼容;使用简单;轻量级的资源消耗;高性能。
Sync Workers(同步workers)
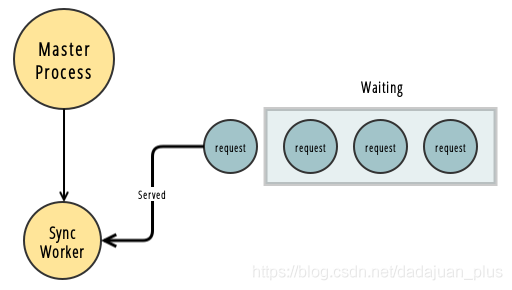
默认的、最简单的worker模式,是同步模式。
每个worker进程,一次只处理一个请求;如果此时又有其他请求被分配到这个worker进程,那只好被阻塞了,要先等第一个请求完成 。并且,一个请求一个进程,并发时,显然很占CPU和内存。
因此,只适合在访问量不大、CPU密集而非I/O密集的情形。
不过也不是没有好处;好处是,即使一个worker进程crash了,也只会影响一个请求。
Async Workers(异步workers)
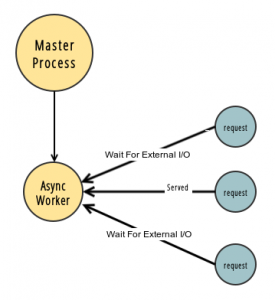
有Gevent和Eventlet两种,都是基于Greenlet实现的。
用了异步worker,就能同时处理不止一个请求,就不会出现上面同步worker那样,一个请求就把后续请求都block阻塞住的情况了。
Gevent是一个Python网络函数库,它通过Greenlet协程+libev快速事件循环,实现了异步模型。有了Gevent,切换Greenlet时就不再需要手动切换,而是当一个Greenlet遇到I/O时,Gevent能自动切换Greenlet,保证总有Greenlet在运行,而无需等待I/O。
异步worker是怎样实现并发,使得一个worker就能同时处理很多请求的呢?
以Gevent为例,每个请求的连接是一个Greenlet协程。Gevent虽然只有一个线程、同时只能处理一个请求,但是在这个请求的异步事件没准备好、进入IO等待时,能主动yield让出控制权、而不是阻塞其他请求的协程,而是先让其他协程执行,当自己的IO准备好时,事件循环会将它从yield让出控制权的地方,继续恢复执行。
这样,Gevent就能在不同请求间不断切换,从而实现并发,以充分利用CPU、减少IO等待。并且,因为切换的Greenlet是“微线程”,它操作的维度是函数,而不是线程/进程,所以来回切换的开销,就没有那么大。
就我个人理解,同步worker和Gevent异步worker,这两种worker类型是最常用的。一般来说,我们的web app多半属于外部IO密集型(总要访问db、访问第三方服务等等),所以用Gunicorn的Gevent异步worker,就非常合理。
而如果你的web app是CPU密集型,或者你希望请求之间不要互相影响,那么可以选择Gunicorn的同步worker。
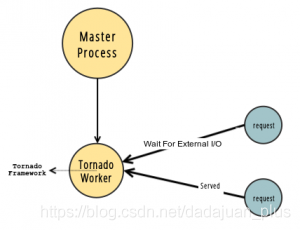
Tornado Workers
用来配合Tornado使用。
Tornado是一个Python框架和网络库,可以提供异步IO非阻塞型模型,来处理长延时请求。
AsyncIO Workers
分成gthread和gaiohttp两种模式。
gaiohttp利用aiohttp库,在服务端和客户端执行异步IO操作。支持web socket。
gthread是一种全线程worker,worker与线程池保持连接,线程会等待接收请求,一个请求一个线程。在Gunicorn启动时,除了可配置worker进程数,还可以配每个进程里的thread线程数。
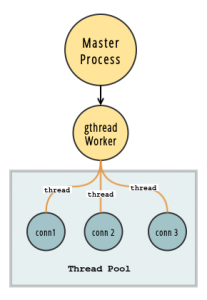
Gunicorn是怎样实现高并发的
Gunicorn启动时,就把worker进程预先fork出来了。当多个请求到来的时候,会轮流复用这些worker进程,从而能提高服务器的并发负载能力。至于worker数的配置,一般推荐2CPU数+1。这样推荐,背后的想法是,在任何时间,都有大概一半的worker是在做I/O,剩下一半才是需要CPU的。如果在开多进程的同时,也开多线程(也就是选择gthread类型的worker),那么,配置总的并发数(worker进程数线程数),仍然建议2*CPU数+1。
flask+Gunicorn(gevent)高并发的解决方法探究如下:
方案一:使用gevent做协程,从而解决高并发的问题,通过Gunicorn(with gevent)的形式对app进行包装,从而来启动服务
1 | # 使用gevent做异步(默认worker是同步的) 多进程+协程 |
方案二: 将运行的信息加载到配置文件中
使用gunicorn + gevent 开启高并发
1 | # 多进程 |
执行 :1
gunicorn -c gunicorn_config.py flask_server:app
协程 第三方封装库
gevent = greenlet + python.monkey(底层使用 libevent 时间复杂度: O(N * logN))
meinheld = greenlet + picoev (时间复杂度: O(N) )
eventlet
1 | meinheld和gevent都能实现异步,但是测评中meinheld比gevent的性能好很多,不过因为meinheld支持的比较少,一般都是配合gunicorn使用的。下面分析一下meinheld和gevent性能差距主要原因,分别使用的是picoev和lievent。 |
Gunicorn源码概览
gunicorn源码的入口文件为main.py1
2from gunicorn.app.wsgiapp import run
run()
在初始化加载相关配置文件后,调用 Arbiter(self).run()方法
1 | def run(self): |
其中self.start()会根据配置文件加载相关运行信息,包括worker工作方式。在manage_workers代码如下
1 | def manage_workers(self): |
在spawn_worker中有初始化进程代码
1 | def spawn_worker(self): |
在init_process中就能够选择不同类型的worker了。