数据的一致性
定义
- 一些分布式系统通过复制数据来提高系统的可靠性和容错性,并且将数据的不同副本存放在不同的机器
- 在数据有多份副本的情况下,如果网络、服务器或者软件出现故障,会导致部分副本写入成功,部分副本写入失败。这就造成各个副本之间的数据不一致,数据内容冲突。
模型
- 强一致性
要求无论更新操作时在那一个副本之行,之后所有的读操作都要获得最新的数据。
- 弱一致性
用户读到某一操作对系统特定数据的更新需要一段时间,我们称之为“不一致窗口”。
- 最终一致性
是弱一致的一种特例,保证用户最终能够读取到某操作对系统特定数据的更新;
从客户端来讲,有可能暂时获取不到最新的数据,但是最终还是可以访问最新的。
从服务来讲,数据存储并复制到分布整个系统超过半数的节点,以保证数据最终一致性。
最终一致性
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
因果一致性
如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将返回更新后的值,且一次写入将保证取代前一次写入。与进程A无因果关系的进程C的访问遵守一般的最终一致性规则。
“读己之所写(read-your-writes)”一致性
当进程A自己更新一个数据项之后,它总是访问到更新过的值,绝不会看到旧值。这是因果一致性模型的一个特例。
会话(Session)一致性
这是上一个模型的实用版本,它把访问存储系统的进程放到会话的上下文中。只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统的保证不会延续到新的会话。
单调(Monotonic)读一致性
如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。
单调写一致性
系统保证来自同一个进程的写操作顺序执行。要是系统不能保证这种程度的一致性,就非常难以编程了。
最终一致性解决方案
可以选择分布式事务框架方案,目前主流的分布式事务框架大致可分为3类实现 :
基于XA协议的两阶段提交(2PC)方案
基于支付宝最早提出的TCC(Try、Confirm、Cancel)方案
基于ebay最早提出的消息队列异步确保方案
此外还有较轻的解决方案,业务系统可以根据自身需要,选择通过幂等/重试、状态机、恢复日志、异步校验等技术来确保最终一致性。
分布式事务框架
最终一致性由分布式事务框架保证,业务程序员对框架细节完全透明。
劣势
- 由于分阶段提交协议本身的脆弱性,主流分阶段提交协议如2PC,3PC, TCC都无法完全确保最终一致性,要采用异步校验的手段兜底。
- 分阶段提交协议带来的高延迟,多次协议通信RTT带来的时间损耗。
- 基于消息队列异步确保的分布式事务框架实现,需要考虑消息可靠性和业务侵入问题。
优势
- 分布式事务被框架封装成切面,业务开发只需关心纯业务。
- 分布式事务的代码开发量大大减少。
重试
重试机制可以使分布式不一致数据自动恢复,前提是重试接口要提供幂等保证。重试机制是达成分布式最终一致性的重要手段。例如,超时重传是TCP协议保证数据可靠性的一个重要机制,核心思想其实就是重试。
同步重试 : 在上次请求失败或超时,程序再次发起同步调用请求。后端程序不推荐同步重试,其一因为同步等待占用系统线程资源,其二因为重试引起的流量放大,可能导致系统雪崩。
异步重试 : 通过异步系统(消息队列或调度中间件)对失败或超时请求再次发起调用。推荐这种方式的重试,重试的时间间隔可以设置为根据重试次数指数增长,超过重试阈值仍未成功,可以报警通知并由人工订正。
幂等
用通俗的话来说就是 : 相同的操作执行多次 和 执行一次产生的效果是一样的。有的操作是天然幂等的,如查询、删除操作。有的操作是人为使其幂等,例如TCP的超时重传操作就是幂等的,无论客户端将一个seq字节传送多少次,服务端窗口只会用一次该字节。
状态机
状态机是表示实体的状态根据条件转移的数学模型。通过状态机模型,系统可以判断当前不一致状态,以及如何校正不一致状态到一致状态。这样说可能比较抽象,我们拿发微信群红包的例子来说明。当你点开发红包按钮,输入总金额、红包个数、标题,点击支付成功后。
恢复日志
恢复日志是程序现场的记录,也是业务数据恢复的重要依据。恢复日志log要求全局唯一的requestId来标示请求(实际的业务场景可采用不会重复有含义的业务id),出现异常,可以根据requestId维度redo和undo业务操作,恢复日志具体可分为三部分 :
requestId请求开始时,记录REQUEST START requestId
本地修改时,记录全部的(requestId,x,originalValue, destValue)四元组,x代表操作对象,修改前x的值为originalValue,本次修改的目的操作值为destValue
requestId结束时,记录REQUEST End requestId
恢复日志是系统从不一致的状态恢复到一致状态的重要数据,丢失恢复日志,意味着不一致可能无法恢复。为什么是可能,因为有时可以通过状态机对不一致的状态进行恢复。
异步校验
通过异步校验,可以发现分布式系统中的异常状态,并通过恢复日志进行脚本批量恢复或者人工处理恢复,根据校验的粒度有 :
根据业务实体id校验,使用消息队列,将需要校验业务id投递给校验系统,进行异步校验。
根据时间维度批量校验,使用异步调度框架,根据时间粒度批量获取进行异步校验。
Paxos(Lamport):
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。
基于消息传递通信模型的分布式系统,不可避免的会发生以下错误:进程可能会慢、被杀死或者重启,消息可能会延迟、丢失、重复,在基础Paxos场景中,先不考虑可能出现消息篡改即拜占庭错误的情况。
Paxos算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
主要有三类节点:
提议者(Proposer):提议一个值;
接受者(Acceptor):对每个提议进行投票;
告知者(Learner):被告知投票的结果,不参与投票过程。
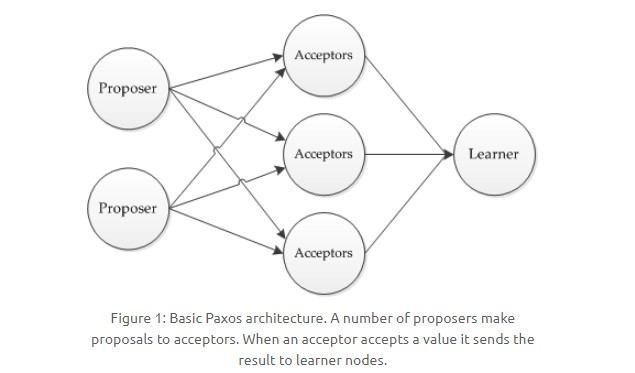
过程:
规定一个提议包含两个字段:[n, v],其中 n 为序号(具有唯一性),v 为提议值。
下图演示了两个 Proposer 和三个 Acceptor 的系统中运行该算法的初始过程,每个 Proposer 都会向所有 Acceptor 发送提议请求。

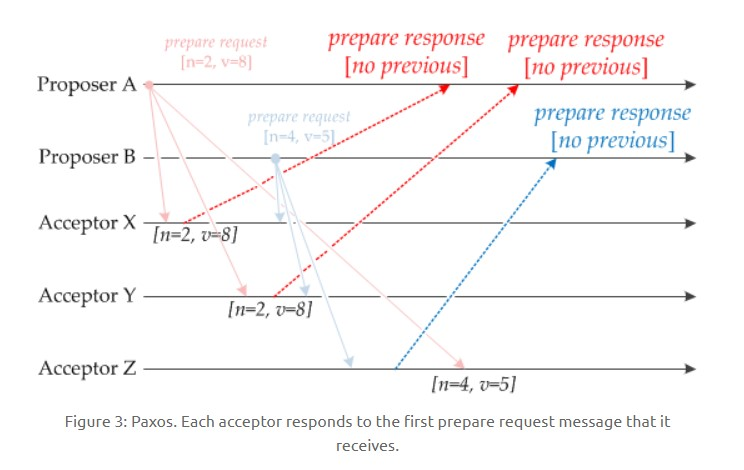
当 Acceptor 接收到一个提议请求,包含的提议为 [n1, v1],并且之前还未接收过提议请求,那么发送一个提议响应,设置当前接收到的提议为 [n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
如下图,Acceptor X 在收到 [n=2, v=8] 的提议请求时,由于之前没有接收过提议,因此就发送一个 [no previous] 的提议响应,并且设置当前接收到的提议为 [n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。
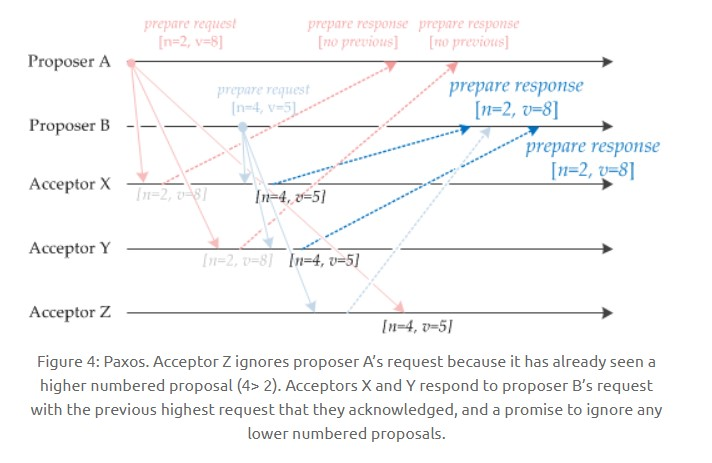
如果 Acceptor 接受到一个提议请求,包含的提议为 [n2, v2],并且之前已经接收过提议 [n1, v1]。如果 n1 > n2,那么就丢弃该提议请求;否则,发送提议响应,该提议响应包含之前已经接收过的提议 [n1, v1],设置当前接收到的提议为 [n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
如下图,Acceptor Z 收到 Proposer A 发来的 [n=2, v=8] 的提议请求,由于之前已经接收过 [n=4, v=5] 的提议,并且 n > 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 [n=4, v=5] 的提议请求,因为之前接收到的提议为 [n=2, v=8],并且 2 <= 4,因此就发送 [n=2, v=8] 的提议响应,设置当前接收到的提议为 [n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。
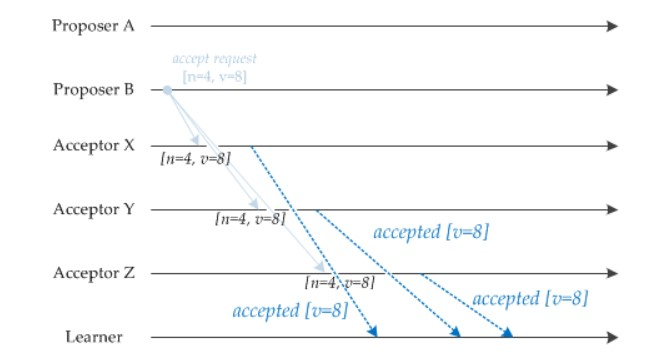
当一个 Proposer 接收到超过一半 Acceptor 的提议响应时,就可以发送接受请求。
Proposer A 接受到两个提议响应之后,就发送 [n=2, v=8] 接受请求。该接受请求会被所有 Acceptor 丢弃,因为此时所有 Acceptor 都保证不接受序号小于 4 的提议。
Proposer B 过后也收到了两个提议响应,因此也开始发送接受请求。需要注意的是,接受请求的 v 需要取它收到的最大 v 值,也就是 8。因此它发送 [n=4, v=8] 的接受请求。

Acceptor 接收到接受请求时,如果序号大于等于该 Acceptor 承诺的最小序号,那么就发送通知给所有的 Learner。当 Learner 发现有大多数的 Acceptor 接收了某个提议,那么该提议的提议值就被 Paxos 选择出来。
Raft算法
Raft算法适用于一个管理日志一致性的协议,相比于Paxos协议,Raft更易于理解和实现。
Raft将一致性算法分为了几个部分,包括领导选取(Leader Selection),日志复制(log replication),安全(safe)
分布式存储系统通过维护多个副本来提高系统的可用性,难点在于分布式存储系统的核心问题,维护多个副本的一致性。
Raft协议基于复制状态机:
- 一组server从相同的初始状态起,按相同的顺序执行相同的命令,最终会达到一致的状态。
- 一组server记录相同的操作日志,并以相同的顺序应用到状态机。
Raft有一个明确的使用场景,管理复制日志的一致性。每台机器保存一份日志,日志来源于客户端的请求,包含一系列的命令,状态机会按顺序执行这些命令。
节点类型
引入主节点,通过竞选。
节点类型:Follower、Candidate 和 Leader
Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
选主流程:
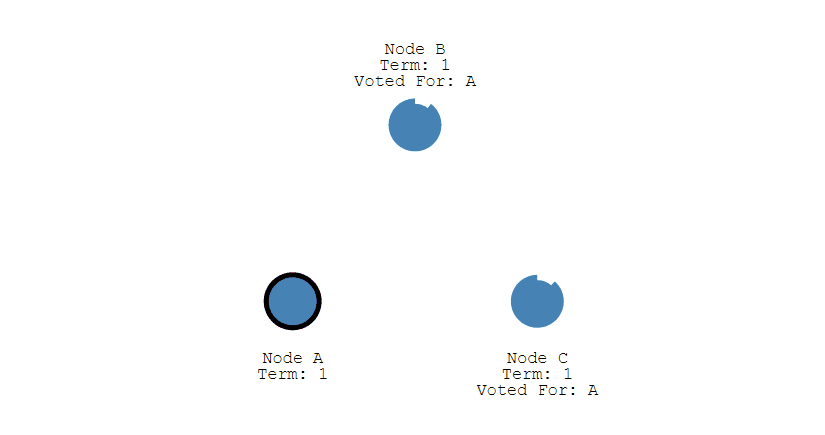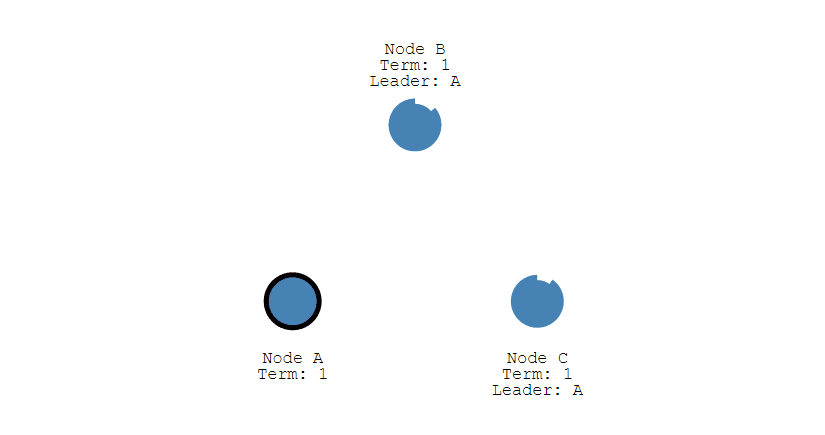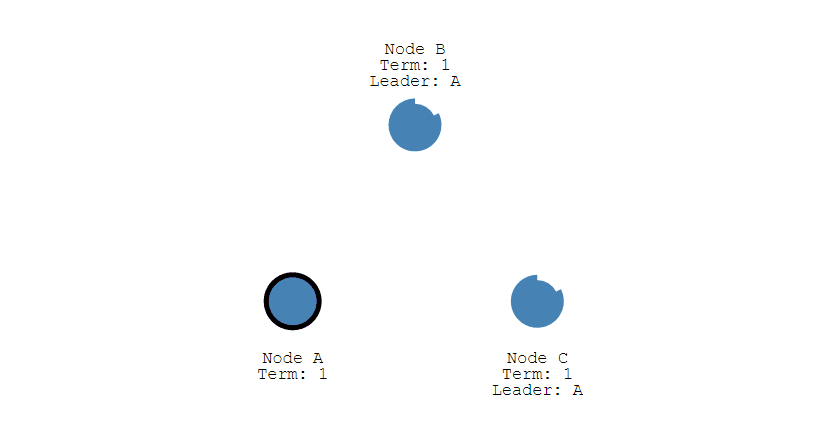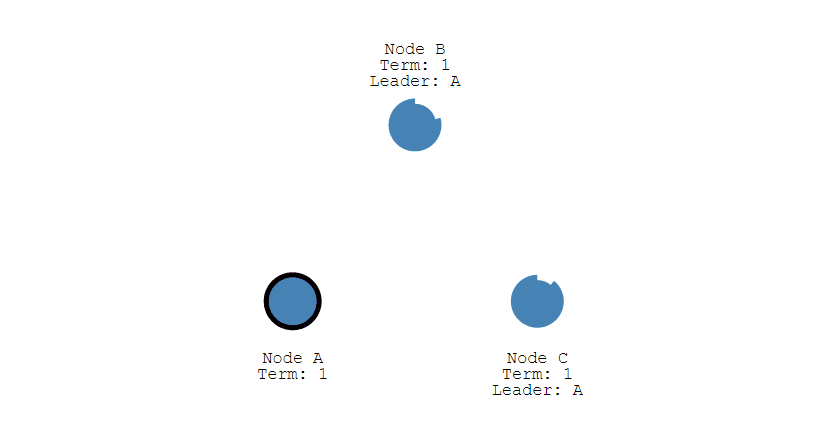
① 下图表示一个分布式系统的最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
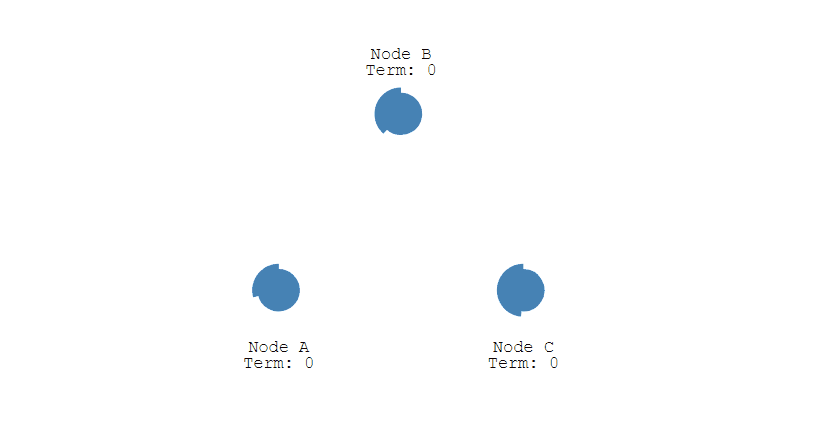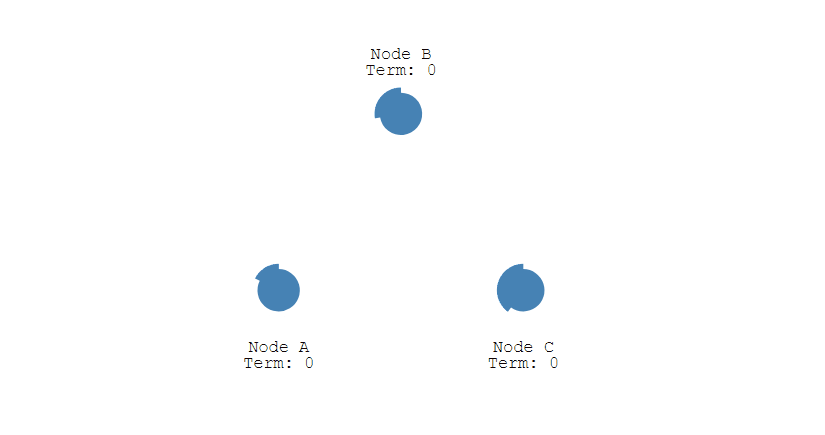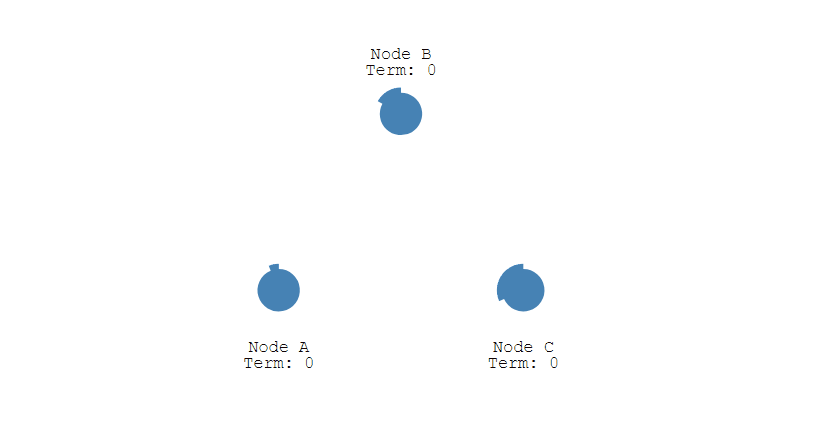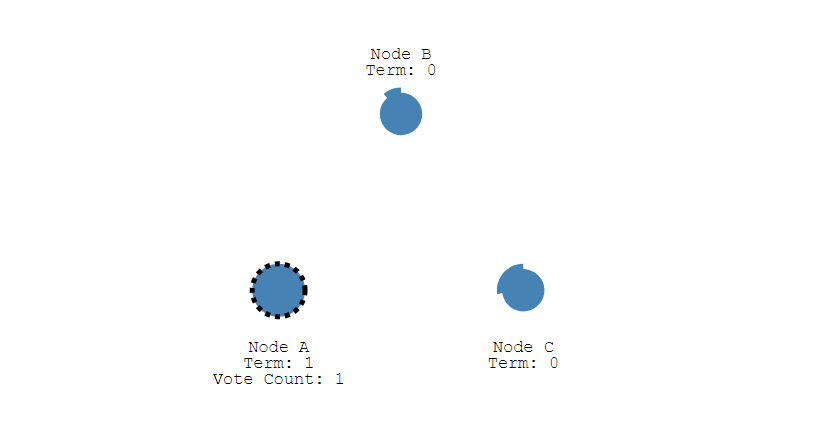
② 此时 A 发送投票请求给其它所有节点。
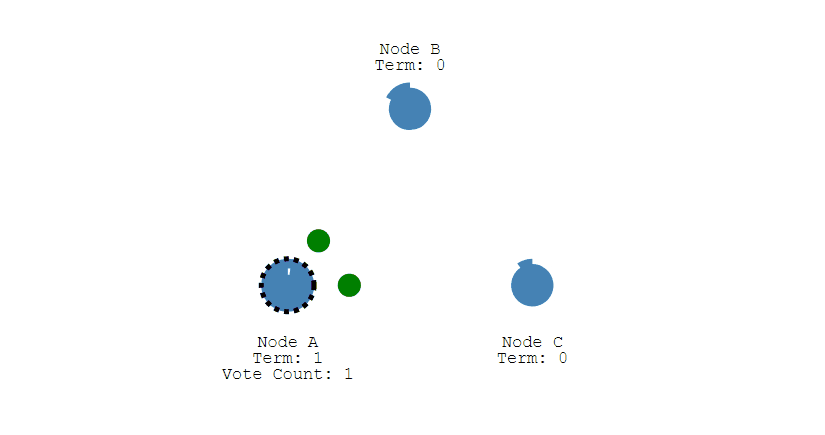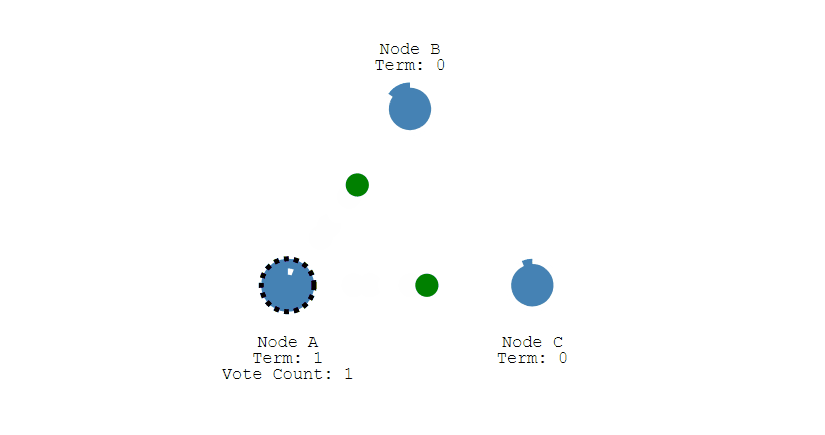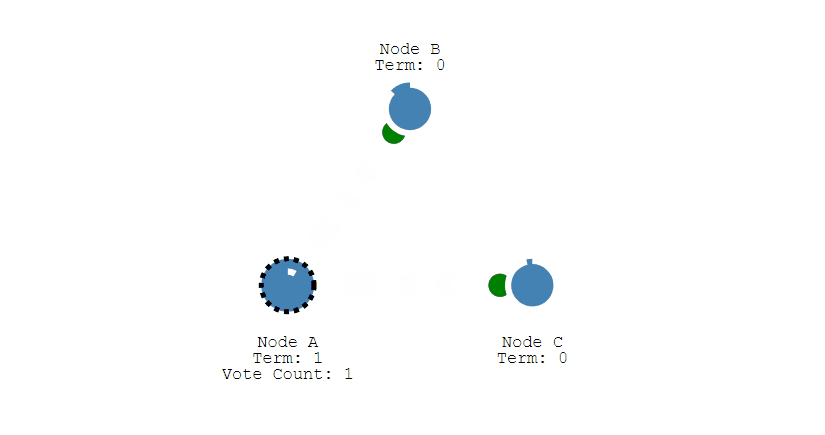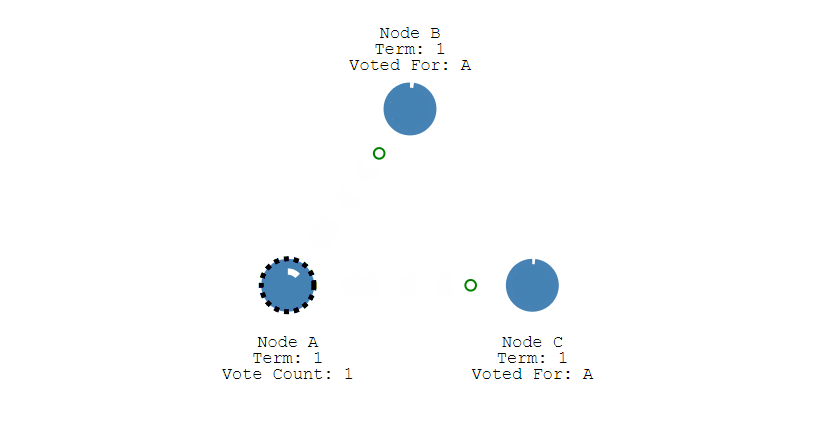
③ 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
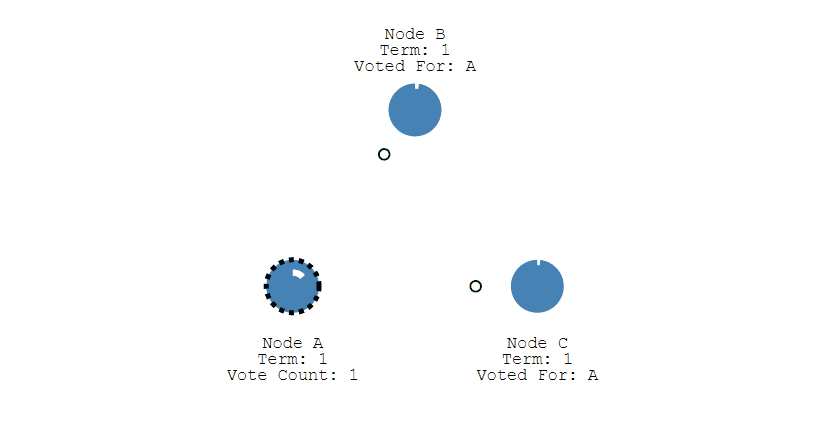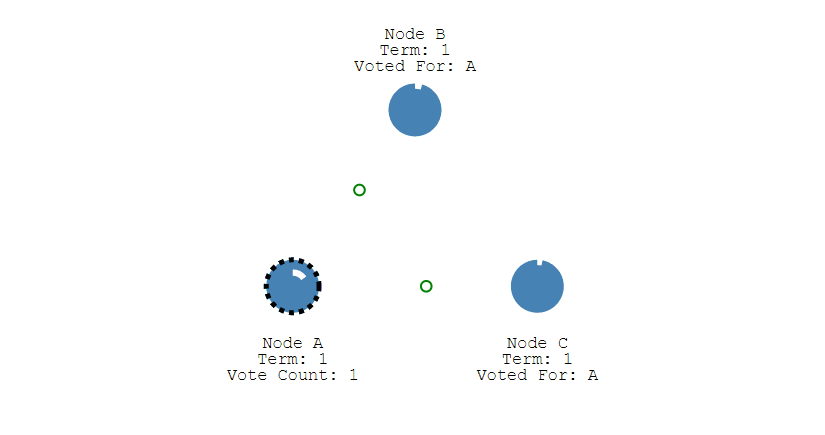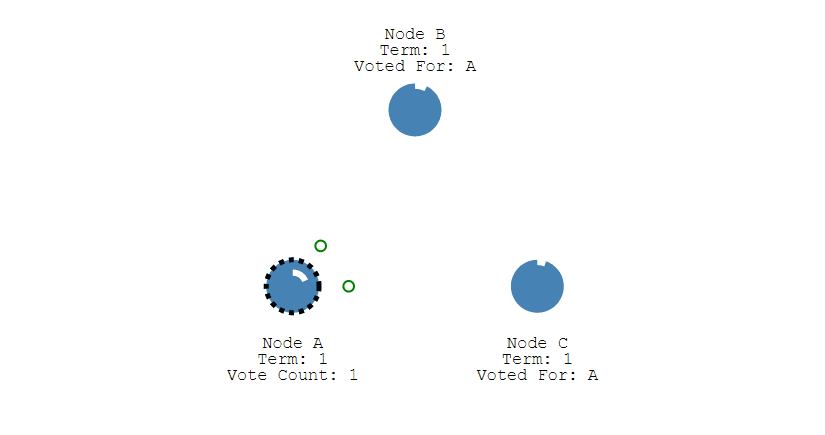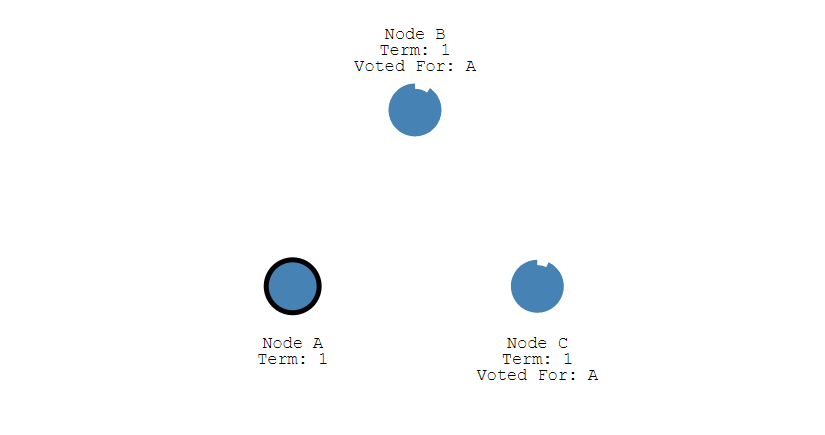
④ 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
日志复制过程:
一旦leader被选举成功,就可以对客户端提供服务了。客户端提交每一条命令都会被按顺序记录到leader的日志中,每一条命令都包含term编号和顺序索引,然后向其他节点并行发送AppendEntries RPC用以复制命令(如果命令丢失会不断重发),当复制成功也就是大多数节点成功复制后,leader就会提交命令,即执行该命令并且将执行结果返回客户端,raft保证已经提交的命令最终也会被其他节点成功执行。leader会保存有当前已经提交的最高日志编号。顺序性确保了相同日志索引处的命令是相同的,而且之前的命令也是相同的。当发送AppendEntries RPC时,会包含leader上一条刚处理过的命令,接收节点如果发现上一条命令不匹配,就会拒绝执行。