基于Term的查询
- Term的重要性
- Term是表达语意的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理Term。
- 特点
- Term Level Query:Term Query/Range Query/Exists Query/Prefix Query/Wildcard Query
- 在ES中,Term查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
- 可以通过Constant Score将查询转换成一个Filtering,避免算分。
1 | POST /product/_bulk |
基于全文本的查找
- 基于全文本的查找
- Match Query/ Match Phrase Query /Query String Query
- 特点
- 索引和搜索时都会进行分词,查询字符串先传递一个合适的分词器,然后生成一个供查询的词项列表
- 查询时候,会先对输入的查询进行分词,然后每个词项逐个进行底层的查询,最终将结果进行合并。每个文档生成一个算分。

结构化搜索
- 结构化搜索是指对结构化数据的搜索
- 日期,布尔河数字都是结构化的
文本也可以是结构化的。
ES中的结构化搜索
- 布尔、时间、日期和数字这类结构化数据,有精确的格式,可以对这些格式进行逻辑操作。包括比较数字或时间的范围,或判定两个值的大小。
- 结构化的文本可以做精确匹配或者部分匹配,Term查询和Prefix前缀查询
- 结构化结果只有是或否两个值,根据场景需要,可以决定结构化搜索是否需要打分
1 | POST /product/_bulk |
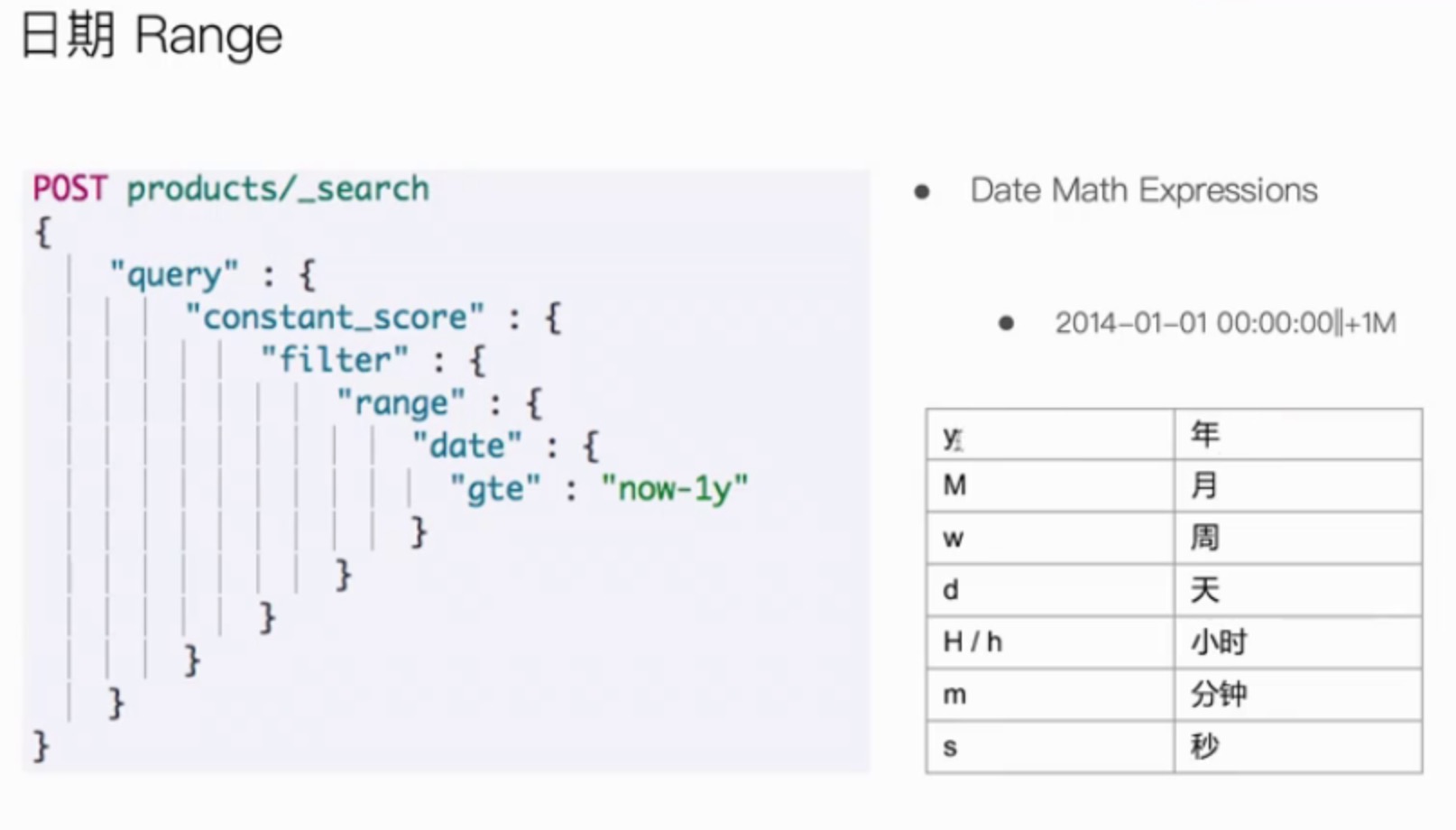
日期range
相关性算分
相关性-Relevance
- 搜索的相关性算分,描述了一个文档和查询语句匹配的程度。ES会对每个匹配查询条件的结果进行算分_score
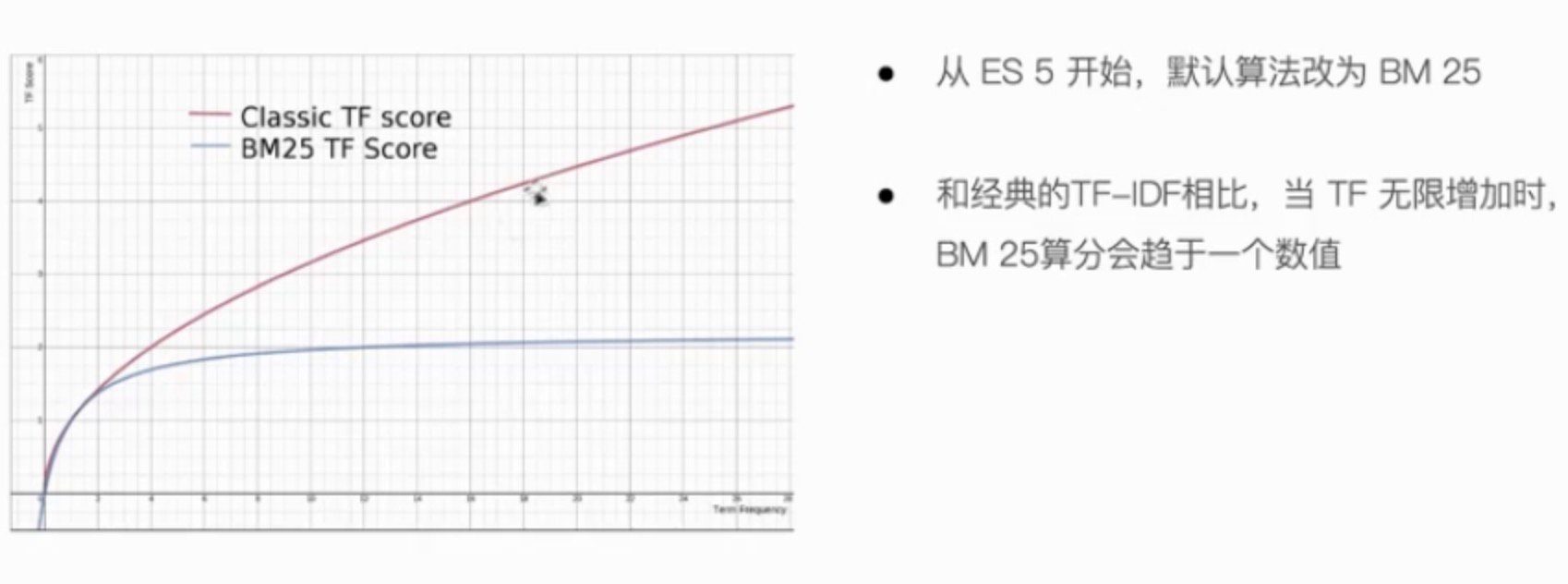
- 打分的本质是排序,需要把最符合用户需求的文档排在前面。ES5之前,默认的相关性算分采用TF-IDF,现在采用BM25
1 | 词 文档id |
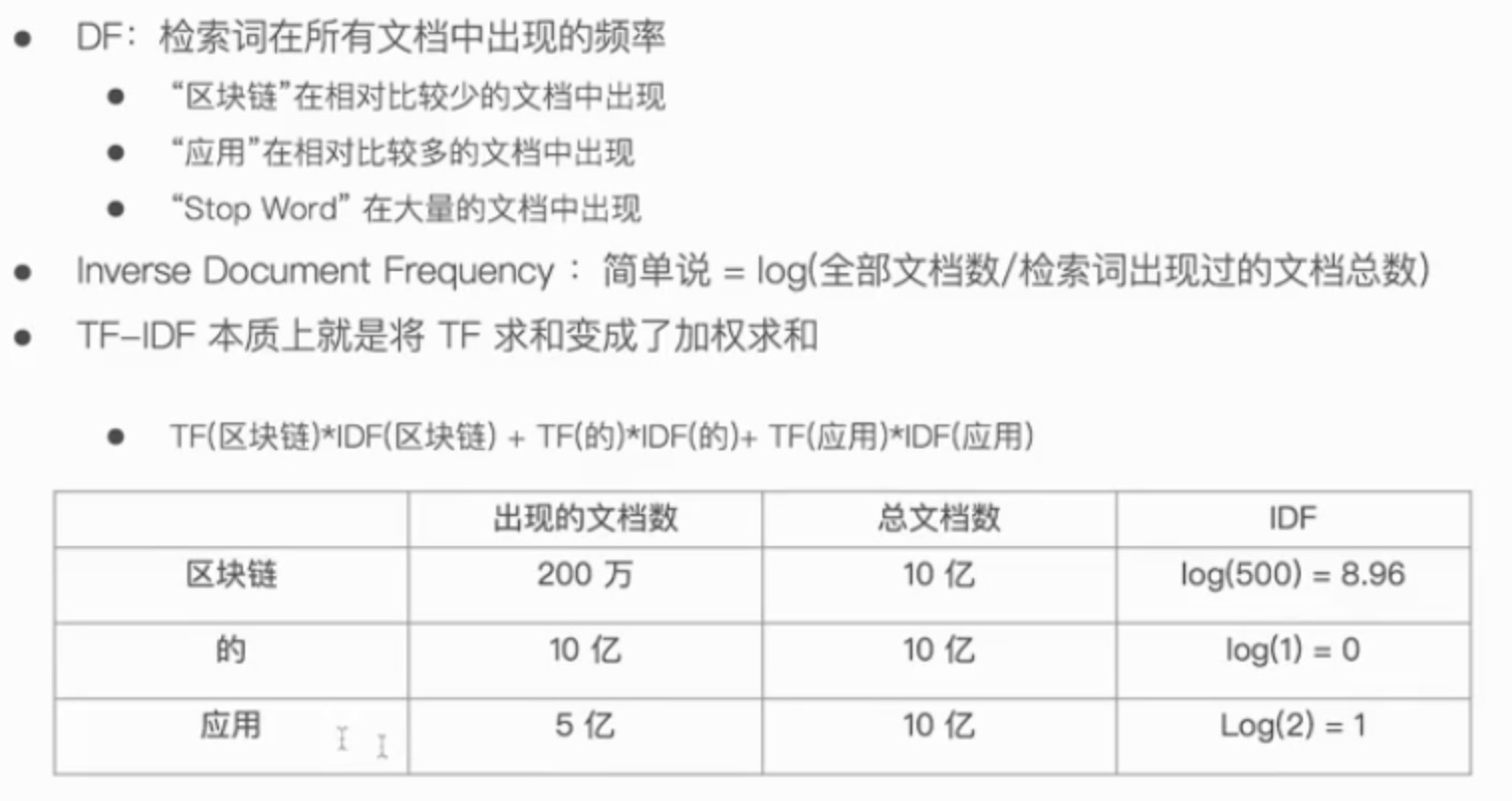
词频 TF
- Term Frequency:检索词在一篇文档中出现的频率
- 检索词出现的次数除以文档的总字数
- 度量一条查询和结果文档相关性的简单方法:简单将搜索中每一个词的TF进行相加
- TF(区块链) + TF(的) +TF(应用)
- Stop Word
- “的”在文档中出现了很多次,但是对贡献相关度几乎没有用处,不应该考虑它们的TF
逆文档频率
TF-IDF的概念
- TF-IDF被公认为是检索领域最重要的发明
- 除了在信息检索,在文献分类和其他相关领域有着非常广泛的应用
现代搜索引擎,对TF-IDF进行了大量细微的优化
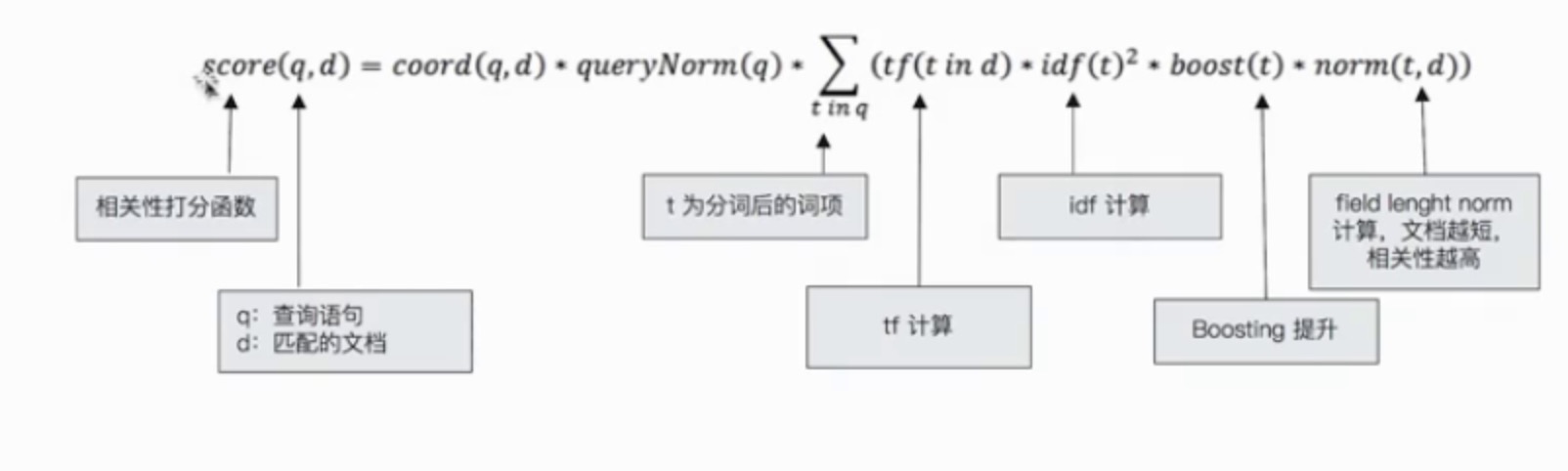
评分公式
- BM25
Query Context & Filter Context
Query Context: 相关性算分,Filter Context: 不需要算分
bool查询
- 一个 bool查询,是一个或者多个查询子句的组合,总共包括4种子句。其中两种会影响算分,2种不影响算分
- 相关性并不只是全文检索的专利,也适用于yes|no的子句,匹配的子句越多,相关性评分越高。如果多条查询子句被合并为一条查询子句,比如bool查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。
1 | must : 必须匹配,贡献算分 |
单字符串多字段查询
1 | POST blog/_search |
三种场景:
- 最佳字段(Best Fields):当字段之间相互竞争,又相互关联。例如title和body这样的字段。评分来自最匹配字段
- 多数字段(Most Fields):处理英文内容时,一种常见的手段是,在主字段,抽取词干,加入同义词,以匹配更多的文档。
- 混合字段(Cross Field):对于某些实体,需要在多个字段中确认信息,单个字段只是整体的一部分。
1 | POST blogs/_search |